RAG - Dotando de Memoria a tu Agente. Parte 2

Preparando la infraestructura: Base de datos y dependencias
Podrás encontrar el código de este artículo en: https://github.com/aperezl/ai-fullstack-serie/tree/rag-2
Antes de poder indexar o recuperar datos, necesitamos una base de datos PostgreSQL con la extensión pgvector habilitada.
Paso 1: Configurar PostgreSQL con `pgvector`
Para esta serie de artículos, recomendamos usar un servicio gestionado que soporte pgvector de forma nativa, como Neon o Supabase. Esto nos abstrae de la complejidad de la instalación y mantenimiento.
Instrucciones para Neon:
- Ve al dashboard de tu proyecto en Vercel.
- Navega a la pestaña "Storage" y crea una nueva base de datos "Neon".
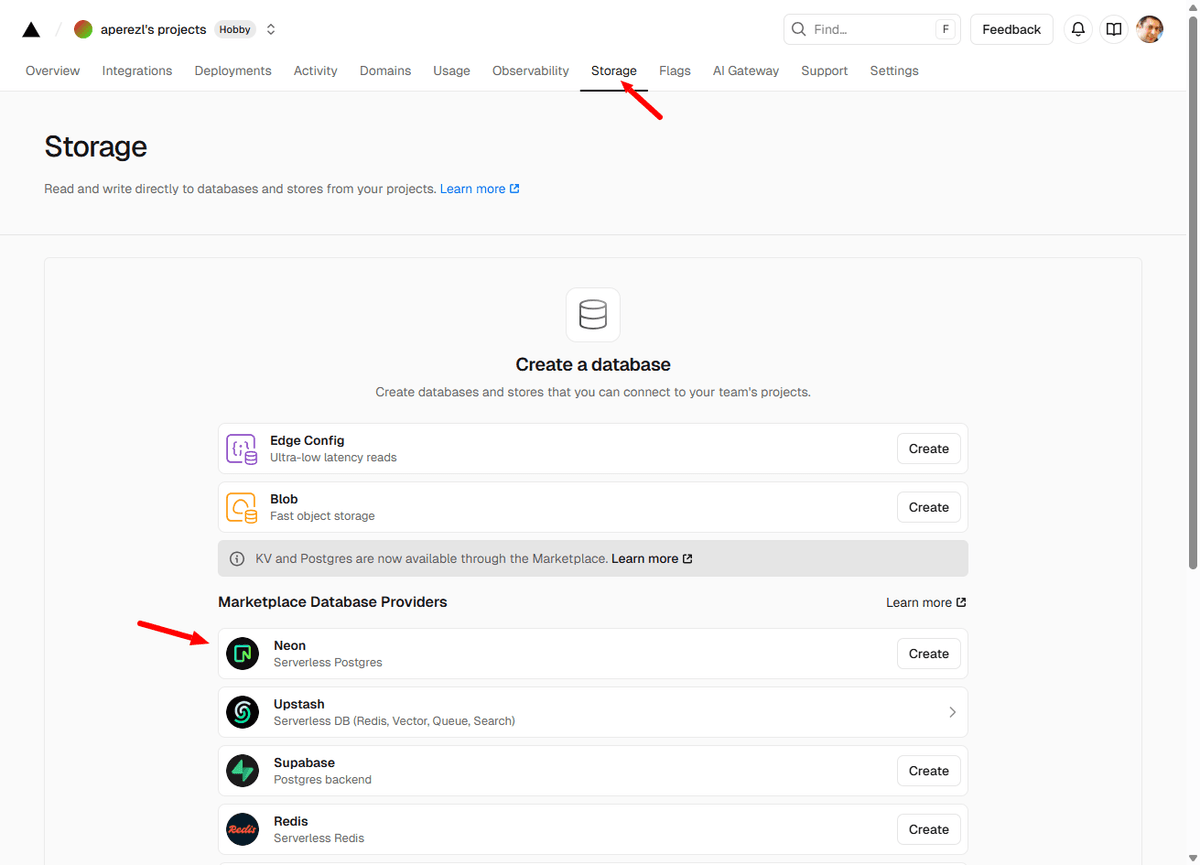
3. Elige una región y haz click en "continue"
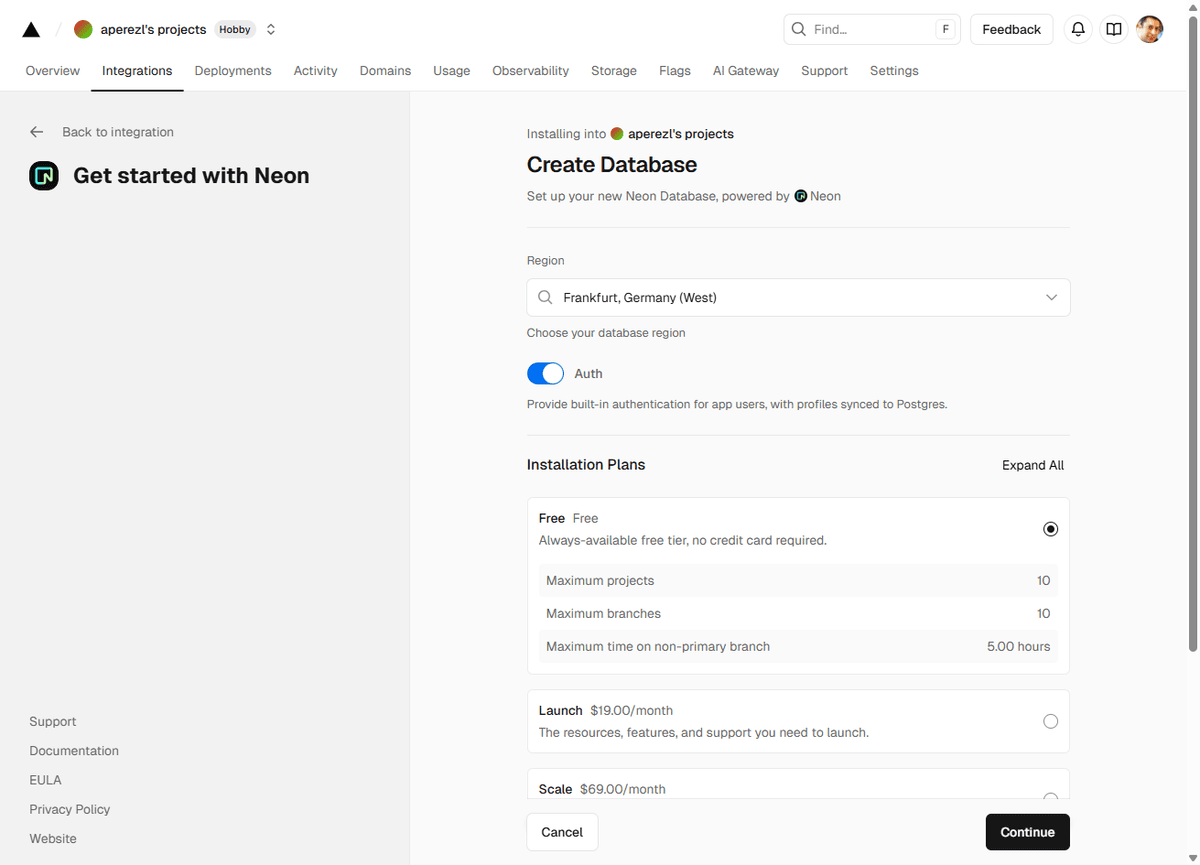
3. Una vez creada, Neon te proporcionará una URL de conexión (POSTGRES_URL). Cópiala.
4. Neon habilita la extensión pgvector por defecto. Para verificarlo, puedes conectar un cliente de PSQL y ejecutar CREATE EXTENSION IF NOT EXISTS vector;.
Añade la URL de conexión a tu archivo .env.local:
DATABASE_URL="TU_URL_DE_CONEXION_AQUI"Paso 2: Instalar dependencias adicionales
Necesitaremos un ORM o cliente de base de datos para interactuar con PostgreSQL, así como bibliotecas para el procesamiento de texto. Usaremos drizzle-orm por su ligereza y seguridad de tipos, y langchain por sus utilidades de chunking.
pnpm add drizzle-orm postgres @neondatabase/serverless
pnpm add -D drizzle-kit
pnpm add langchain-
drizzle-orm: El ORM que usaremos. -
postgres: El driver de Node.js para PostgreSQL. -
@neondatabase/serverless: Un driver optimizado para entornos serverless como Vercel. -
drizzle-kit: La CLI para gestionar migraciones de la base de datos. -
langchain: Lo usaremos específicamente por suRecursiveCharacterTextSplitter.
Paso 3: Definir el esquema de la base de datos con drizzle
Crearemos un esquema para nuestra tabla de chunks. Esta tabla almacenará el contenido de texto de cada fragmento y su correspondiente embedding vectorial.
Crea el archivo src/lib/db/schema.ts:
import { pgTable, serial, text, timestamp, vector } from 'drizzle-orm/pg-core';
export const chunks = pgTable('chunks', {
id: serial('id').primaryKey(),
content: text('content').notNull(),
embedding: vector('embedding', { dimensions: 768 }).notNull(),
createdAt: timestamp('created_at').defaultNow().notNull(),
});Análisis del esquema:
-
vector('embedding', { dimensions: 768 }): Este es el tipo de dato especial quepgvectorproporciona. Es crucial que el número dedimensionscoincida exactamente con la salida del modelo de embedding que usaremos (text-embedding-004de Google produce vectores de 768 dimensiones).
Paso 4: Crear y ejecutar la migración
Drizzle Kit nos permite generar y ejecutar migraciones SQL a partir de nuestro esquema TypeScript.
- Configurar Drizzle Kit: Crea un archivo
drizzle.config.tsen la raíz del proyecto.
import type { Config } from 'drizzle-kit'
import dotenv from 'dotenv'
dotenv.config({ path: '.env.local' })
export default {
schema: './src/lib/db/schema.ts',
out: './drizzle',
dialect: "postgresql",
dbCredentials: {
url: process.env.DATABASE_URL!,
},
} satisfies Config;2. Añadir scripts a package.json:
"scripts": {
// ...
"db:generate": "drizzle-kit generate",
"db:push": "drizzle-kit push"
}3. Generar y ejecutar la migración:
pnpm db:generate # Crea el archivo SQL de la migración en la carpeta /drizzle
pnpm db:push # Aplica la migración a tu base de datos$ pnpm db:generate
> ai-fullstack-serie@0.1.0 db:generate /ai-fullstack-serie
> drizzle-kit generate
No config path provided, using default 'drizzle.config.ts'
Reading config file /ai-fullstack-serie/drizzle.config.ts'
1 tables
chunks 4 columns 0 indexes 0 fks
[✓] Your SQL migration file ➜ drizzle\0000_easy_khan.sql 🚀
$ pnpm db:push
> ia-fullstack-serie@0.1.0 db:push /ai-fullstack-serie
> drizzle-kit push
No config path provided, using default 'drizzle.config.ts'
Reading config file /ai-fullstack-serie/drizzle.config.ts'
[dotenv@17.2.1] injecting env (2) from .env.local -- tip: 📡 version env with Radar: https://dotenvx.com/radar
Using 'postgres' driver for database querying
[✓] Pulling schema from database...
[✓] Changes appliedTu base de datos PostgreSQL ahora tiene la tabla chunks lista para recibir datos.
Ejercicio 1: Implementando la pipeline de ingesta
Crearemos un script que pueda ser ejecutado desde la línea de comandos para procesar nuestros documentos y poblar la base de datos.
Paso 1: Preparar documentos de muestra
Crea un directorio data/ en la raíz del proyecto y dentro, un archivo conocimiento.md con algún contenido de ejemplo.
# El Vercel AI SDK
El Vercel AI SDK es un kit de herramientas de código abierto diseñado para ayudar a los desarrolladores a construir interfaces de usuario, aplicaciones y agentes de IA con JavaScript y TypeScript.
## Características Principales
- **Compatibilidad con Múltiples Proveedores:** Soporta modelos de OpenAI, Google, Anthropic, y más, permitiendo cambiar de proveedor con una sola línea de código.
- **Streaming de Primera Clase:** Ofrece abstracciones como `useChat` y `streamText` para manejar el streaming de respuestas de forma sencilla, mejorando la experiencia de usuario.
- **Generative UI:** Permite a los LLMs generar componentes de React (RSC) en lugar de solo texto, creando interfaces dinámicas y contextuales.
## Instalación
Para instalar el SDK y el proveedor de Google, ejecuta:
`pnpm install ai @ai-sdk/google`Paso 2: Crear el script de ingesta
Crea el archivo scripts/ingest.ts. Este script contendrá toda la lógica de la pipeline de ingesta.
import { drizzle } from 'drizzle-orm/postgres-js';
import postgres from 'postgres';
import { chunks as chunksSchema } from '../src/lib/db/schema'; // Renombrado para evitar conflicto de nombres
import { promises as fs } from 'fs';
import path from 'path';
import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
import { google } from '@ai-sdk/google';
import { embedMany } from 'ai';
import dotenv from 'dotenv';
dotenv.config({ path: '.env.local' });
// Función auxiliar para dividir un array en lotes de un tamaño específico
function chunkArray<T>(array: T[], chunkSize: number): T[][] {
const result: T[][] = [];
for (let i = 0; i < array.length; i += chunkSize) {
result.push(array.slice(i, i + chunkSize));
}
return result;
}
async function main() {
console.log('Iniciando pipeline de ingesta...');
// 1. Conectar a la base de datos
const connectionString = process.env.DATABASE_URL;
if (!connectionString) {
throw new Error('La variable de entorno POSTGRES_URL no está definida.');
}
const client = postgres(connectionString, { max: 1 });
const db = drizzle(client);
console.log('Conectado a la base de datos.');
// 2. Cargar y Extraer Texto del Documento
const filePath = path.join(process.cwd(), 'data', 'book.md');
const fileContent = await fs.readFile(filePath, 'utf-8');
console.log('Documento cargado.');
// 3. Chunking (División) del Documento
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 512,
chunkOverlap: 50,
});
const textChunks = await splitter.splitText(fileContent);
console.log(`Documento dividido en ${textChunks.length} chunks.`);
// Define el tamaño del lote
const BATCH_SIZE = 100;
const textChunksBatches = chunkArray(textChunks, BATCH_SIZE);
console.log(`Procesando en ${textChunksBatches.length} lotes de hasta ${BATCH_SIZE} chunks cada uno.`);
for (let i = 0; i < textChunksBatches.length; i++) {
const batch = textChunksBatches[i];
console.log(`Procesando lote ${i + 1}/${textChunksBatches.length} con ${batch.length} chunks...`);
// 4. Generación de Embeddings para el lote actual
const embeddingModel = google.textEmbedding('text-embedding-004');
console.log('Generando embeddings para el lote...');
const { embeddings } = await embedMany({
model: embeddingModel,
values: batch,
});
console.log(`Se generaron ${embeddings.length} embeddings para el lote.`);
// 5. Almacenamiento en la Base de Datos Vectorial para el lote actual
const dataToInsert = batch.map((content, j) => ({
content,
embedding: embeddings[j],
}));
console.log('Insertando chunks y embeddings del lote en la base de datos...');
await db.insert(chunksSchema).values(dataToInsert);
console.log(`¡Inserción del lote ${i + 1} completada!`);
}
// Cerrar la conexión
await client.end();
console.log('Pipeline de ingesta finalizada con éxito.');
}
main().catch((error) => {
console.error('Ha ocurrido un error en la pipeline de ingesta:', error);
process.exit(1);
});Análisis a fondo: la pipeline de ingesta
El script scripts/ingest.ts es el arquitecto de la memoria de nuestro agente de IA. Su única y crucial misión es tomar conocimiento en bruto (un archivo de texto) y transformarlo en una base de datos estructurada y semánticamente consultable. Pensemos en este proceso como el trabajo de un bibliotecario meticuloso que no solo cataloga libros, sino que lee cada párrafo, entiende su significado y le asigna una "dirección" única en un vasto mapa de conceptos.
Este script es una pipeline: una serie de pasos que se ejecutan en secuencia, donde la salida de un paso se convierte en la entrada del siguiente. A continuación, desglosamos cada etapa de este proceso.
El arranque: preparando la conexión
Antes de procesar cualquier dato, el script realiza dos acciones preparatorias:
- Carga de variables de entorno: Mediante
dotenv, carga la URL de la base de datos desde.env.local. Esto mantiene nuestras credenciales seguras. - Conexión a la base de datos: Establece la conexión con PostgreSQL y la envuelve en
drizzle, nuestro ORM, que nos permitirá interactuar con la base de datos de forma segura y con TypeScript.
Carga del documento fuente
- ¿Qué hace? Utilizando los módulos
fsypathde Node.js, el script localiza el archivodata/conocimiento.mdy lee su contenido completo en una única variable de tipo string. - ¿Por qué es importante? Este es el punto de partida. Todo el conocimiento que nuestro agente tendrá sobre este tema específico reside en esta cadena de texto inicial.
División en chunks (la fragmentación inteligente)
- ¿Qué hace? Aquí entra en juego
RecursiveCharacterTextSplitterde Langchain. Esta herramienta divide el texto largo en fragmentos más pequeños y manejables (chunks) de un tamaño aproximado de 512 caracteres, con una superposición de 50 caracteres entre ellos. - ¿Por qué es importante?
- Precisión en la búsqueda: Es más efectivo buscar un concepto en un párrafo específico que en un documento de 100 páginas.
- Límites de contexto: Los modelos de IA no pueden procesar textos de longitud infinita. Los chunks aseguran que el contexto que recuperemos sea digerible para el LLM.
- Coherencia semántica: La superposición (
chunkOverlap) garantiza que las ideas que se extienden a través de los límites de los fragmentos no se pierdan, manteniendo el contexto intacto.
Agrupación en lotes (batching)
- ¿Qué hace? El script utiliza la función auxiliar
chunkArraypara agrupar la lista de chunks en "lotes" de 100. En lugar de tener una lista de 500 chunks, ahora tendríamos 5 listas, cada una con 100 chunks. - ¿Por qué es importante? Esta no es solo una optimización, sino un requisito técnico impuesto por la API de Google. El modelo de embedding
text-embedding-004no puede procesar más de 100 textos en una única llamada. El batching asegura que nuestro script respete este límite, haciendo llamadas eficientes y evitando errores.
Generación de embeddings (la traducción semántica)
- ¿Qué hace? Este es el corazón del proceso. El script itera sobre cada lote y envía su contenido a la función
embedMany. El modelo de IA de Google procesa cada chunk y lo convierte en un vector: una lista de 768 números que representa su significado. - ¿Por qué es importante? Un embedding es una "huella digital semántica". Textos con significados similares, como "Guía de instalación" y "¿Cómo se instala?", producirán vectores matemáticamente muy parecidos. Esto es lo que permitirá a nuestro sistema encontrar información relevante aunque el usuario no use las palabras exactas del documento.
Almacenamiento en la base de datos vectorial
- ¿Qué hace? Una vez que tenemos los vectores para un lote de chunks, el script los empareja con su texto original. Luego, utiliza Drizzle (
db.insert) para guardar estos pares(contenido, embedding)como nuevas filas en la tablachunksde nuestra base de datos PostgreSQL. - ¿Por qué es importante? Este es el paso final de persistencia. Al almacenar los vectores en una columna de tipo
vectorgracias apgvector, le damos a nuestra base de datos la capacidad de realizar búsquedas de similitud a alta velocidad.
Al finalizar la ejecución del script, hemos transformado un documento estático en una base de conocimientos dinámica y consultable. No tenemos solo datos en una tabla; hemos construido una memoria estructurada, semántica y lista para que nuestro agente de IA pueda acceder a ella.
Paso 3: Ejecutar el script
Añade un script a tu package.json para ejecutarlo fácilmente:
"scripts": {
// ...
"ingest": "npx -y tsx scripts/ingest.ts"
}Y ejecútalo:
pnpm ingestTras la ejecución, tu tabla chunks en PostgreSQL contendrá los fragmentos de tu documento Markdown junto con sus representaciones vectoriales.
$ pnpm ingest
> ai-fullstack-serie@0.1.0 ingest /ia-fullstack-serie
> npx -y tsx scripts/ingest.ts
[dotenv@17.2.1] injecting env (2) from .env.local -- tip: 📡 auto-backup env with Radar: https://dotenvx.com/radar
Iniciando pipeline de ingesta...
Conectado a la base de datos.
Documento cargado.
Documento dividido en 2 chunks.
Generando embeddings para los chunks...
Se generaron 2 embeddings.
Insertando chunks y embeddings en la base de datos...
¡Inserción completada!
Pipeline de ingesta finalizada con éxito.Ejercicio 2: Integrando la recuperación en la API de chat
Ahora modificaremos nuestro chatbot para que use la base de conocimientos que acabamos de crear.
Paso 1: Crear la función de búsqueda de similitud
Primero, necesitamos una función que, dada una pregunta, encuentre los chunks más relevantes. Añadiremos esta lógica en un nuevo archivo src/lib/ai/rag.ts.
import 'dotenv/config';
import { drizzle } from 'drizzle-orm/postgres-js';
import postgres from 'postgres';
import { chunks } from '../db/schema';
import { google } from '@ai-sdk/google';
import { embed } from 'ai';
import { sql } from 'drizzle-orm';
// Conexión a la BBDD (reutilizable)
const connectionString = process.env.POSTGRES_URL!;
const client = postgres(connectionString);
const db = drizzle(client);
const embeddingModel = google.embedding('text-embedding-004');
export async function findRelevantChunks(query: string, k: number = 3) {
// 1. Generar el embedding para la pregunta del usuario
const { embedding } = await embed({
model: embeddingModel,
value: query,
});
// 2. Búsqueda de similitud en la base de datos vectorial
const similarity = sql<number>`1 - (${chunks.embedding} <=> ${JSON.stringify(embedding)})`;
const relevantChunks = await db
.select({
content: chunks.content,
similarity: similarity,
})
.from(chunks)
.where(sql`${similarity} > 0.5`) // Umbral de similitud para filtrar resultados irrelevantes
.orderBy((t) => sql`(${t.similarity}) DESC`)
.limit(k);
return relevantChunks;
}Análisis de la función de búsqueda:
-
embed({ value: query }): Usamosembed(singular) para vectorizar la pregunta del usuario. -
<=>: Este es el operador de distancia de coseno que proporcionapgvector. Una distancia más pequeña significa una mayor similitud. -
1 - (distancia): Convertimos la distancia en una puntuación de similitud (donde un valor más alto es mejor) restándola de 1. -
where(sql${similarity} > 0.5): Es una buena práctica filtrar por un umbral de similitud para evitar incluir contexto que no sea relevante en absoluto.
Paso 2: Crear la API de chatbot para usar RAG
Finalmente, creado nuestro src/app/api/rag/route.ts para que llame a findRelevantChunks y aumente el prompt.
import { google } from '@ai-sdk/google';
import { streamText, convertToModelMessages, UIMessage } from 'ai';
import { findRelevantChunks } from '@/lib/ai/rag'; // Importamos nuestra nueva función
export const maxDuration = 30;
export async function POST(req: Request) {
try {
const { messages }: { messages: UIMessage[] } = await req.json();
const lastUserMessage = messages[messages.length - 1];
// 1. Realizar la búsqueda de similitud para obtener contexto
const relevantChunks = await findRelevantChunks(lastUserMessage.content as string);
// 2. Construir el contexto para el prompt
const context = relevantChunks.map(chunk => chunk.content).join('\n---\n');
// 3. Crear el prompt aumentado
const systemPrompt = `
Eres un asistente experto en el Vercel AI SDK. Responde a la pregunta del usuario
basándote únicamente en el siguiente contexto. Si la respuesta no se encuentra en el
contexto, responde "No tengo suficiente información en mi base de conocimientos para responder a esa pregunta".
Contexto:
---
${context}
---
`;
// 4. Llamar al LLM con el prompt aumentado
const result = await streamText({
model: google('gemini-2.5-pro'),
system: systemPrompt,
messages: convertToModelMessages(messages),
});
return result.toUIMessageStreamResponse();
} catch (error) {
console.error("Error en la API de chat con RAG:", error);
return new Response("Un error inesperado ha ocurrido.", { status: 500 });
}
}Poniendo a prueba nuestro agente con memoria
Ahora que hemos construido tanto la pipeline de ingesta como la API de recuperación, es el momento de la verdad: probar cómo se comporta nuestro agente. Para ello, utilizaremos una herramienta muy popular en VS Code, la extensión REST Client, que nos permite enviar peticiones HTTP directamente desde un archivo de texto.
Paso 1: Iniciar el servidor de desarrollo
Primero, asegúrate de que tu aplicación Next.js esté en ejecución. Abre tu terminal y ejecuta el siguiente comando:
pnpm devEsto iniciará el servidor de desarrollo, generalmente en http://localhost:3000.
Paso 2: Crear un archivo de prueba para la API
Para mantener nuestro proyecto organizado, crea una nueva carpeta llamada contrib en la raíz de tu proyecto, y dentro de ella, un archivo llamado test.http.
/
├── contrib/
│ └── test.http
├── src/
...Pega el siguiente contenido en tu nuevo archivo contrib/test.http. Hemos preparado dos peticiones: una que es relevante para nuestro conocimiento y otra que no lo es.
### Petición 1: Pregunta relevante para el contexto
# Esta pregunta debería encontrar chunks similares en la base de datos.
POST http://localhost:3000/api/rag
Content-Type: application/json
{
"messages": [
{
"id": "1",
"role": "user",
"parts": [
{
"type": "text",
"text": "¿Como puedo instalar Vercel AI SDK?"
}
]
}
]
}
### Petición 2: Pregunta irrelevante para el contexto
# Esta pregunta no debería encontrar ninguna coincidencia relevante.
POST http://localhost:3000/api/rag
Content-Type: application/json
{
"messages": [
{
"id": "1",
"role": "user",
"parts": [
{
"type": "text",
"text": "¿Como puedo instalar Angular?"
}
]
}
]
}Paso 3: Probar la API con REST Client
Si tienes la extensión REST Client instalada en VS Code, verás un pequeño botón Send Request justo encima de cada petición POST.
- Haz clic en el
Send Requestde la Petición 1. - Observa la respuesta que aparece en una nueva pestaña a la derecha.
- A continuación, haz clic en el
Send Requestde la Petición 2 y compara los resultados.
Comprendiendo los resultados
Aquí es donde vemos la magia (y la lógica) de nuestro sistema RAG en acción. Las respuestas que obtendrás serán drásticamente diferentes.
Escenario 1: Respuesta con contexto encontrado
Al enviar la pregunta ¿Qué es el Vercel AI SDK y cuáles son sus características?, ocurre lo siguiente:
- El sistema vectoriza tu pregunta.
- La búsqueda en
pgvectorencuentra una alta similitud con los chunks que extrajimos deconocimiento.md. - Estos chunks se inyectan en el
systemPromptcomo contexto. - El LLM recibe el contexto y la pregunta, y formula una respuesta precisa basada en la información proporcionada.
Respuesta Esperada (aproximada):
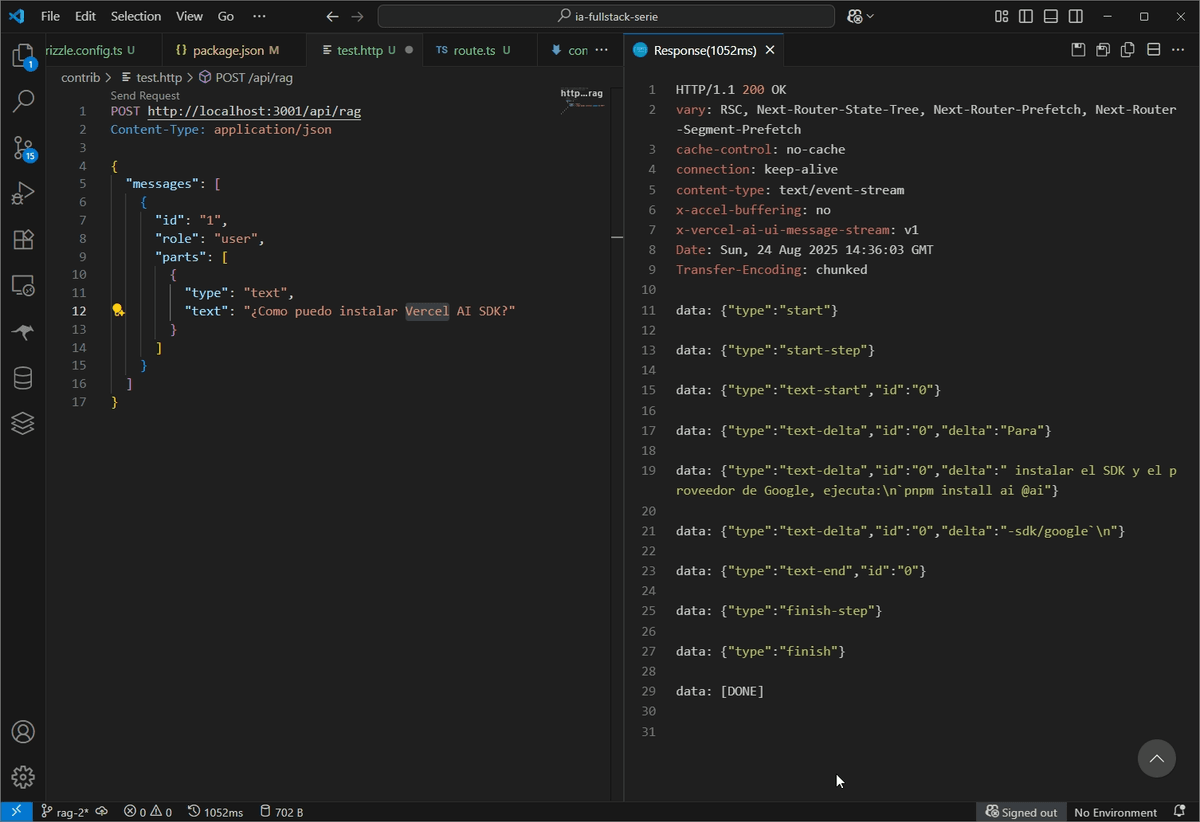
Escenario 2: Respuesta sin contexto encontrado
Cuando envías la pregunta ¿Como puedo instalar Angular?, el proceso es muy diferente:
- El sistema vectoriza la pregunta.
- La búsqueda en
pgvectorcompara este nuevo vector con los de nuestra base de datos. Como no hay ninguna relación semántica entre "Aaron Swartz" y "Vercel AI SDK", la puntuación de similitud será muy baja. - Nuestro umbral (
similarity > 0.5) filtrará todos los resultados. La funciónfindRelevantChunksdevolverá una lista vacía. - El
systemPromptse construirá con un contexto vacío. - El LLM recibirá la instrucción: "Responde basándote *únicamente* en el siguiente contexto. Si la respuesta no se encuentra, di que no tienes información".
Respuesta esperada (exacta):
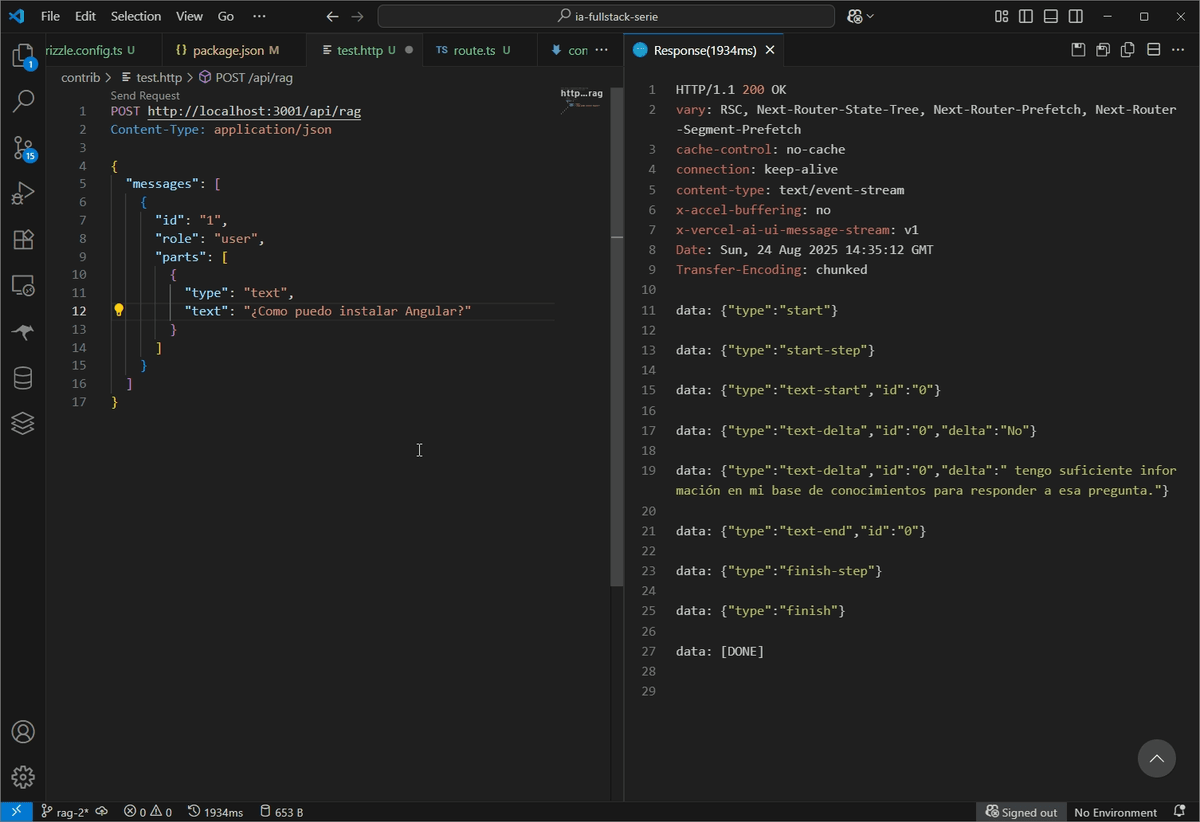
Conclusión de la práctica
Hemos implementado un sistema RAG completo y funcional. Nuestro script de ingesta es capaz de procesar documentos y prepararlos para la búsqueda semántica, y nuestro chatbot ahora está "conectado" a esta base de conocimientos externa. Ya no está limitado a su conocimiento paramétrico; puede responder preguntas basadas en datos específicos que le proporcionamos.
En el ejemplo web completo, veremos este sistema en acción y analizaremos cómo la calidad de las respuestas cambia drásticamente cuando el modelo tiene acceso a un contexto relevante.
Podrás encontrar el código de este artículo en: https://github.com/aperezl/ai-fullstack-serie/tree/rag-2