RAG Avanzado y Agentes Multi-modales. Parte 3

De la persistencia a la inmediatez: Introducción a Cache-Augmented Generation (CAG)
Podrás encontrar el código de este artículo en: https://github.com/aperezl/ai-fullstack-serie/tree/rag-pdf
Hasta ahora, nuestra estrategia de RAG se ha basado en un conocimiento persistente: una base de datos vectorial pre-procesada que nuestro agente consulta. Esta arquitectura es ideal para conocimiento corporativo estable. Pero, ¿qué sucede con la información efímera o de un solo uso? ¿Qué pasa si un usuario quiere discutir un documento ahora mismo, sin la intención de que se convierta en parte del conocimiento a largo plazo del agente?
Ingerir cada documento de un solo uso en nuestra base de datos pgvector es ineficiente y costoso. Contaminaría nuestro conocimiento curado y generaría una sobrecarga innecesaria de procesamiento y almacenamiento. Aquí es donde un patrón arquitectónico más ágil, conocido como Cache-Augmented Generation (CAG), se vuelve indispensable.
¿Qué es CAG?
CAG es una variante de RAG donde el paso de "recuperación" (Retrieval) no se realiza desde una base de datos vectorial persistente, sino desde una caché de contexto temporal generada en tiempo de ejecución. El flujo es el siguiente:
- Carga dinámica: El usuario sube un documento (ej. un PDF).
- Procesamiento en memoria: En lugar de una pipeline de ingesta completa, procesamos el documento "al vuelo": lo cargamos en la memoria del servidor, lo dividimos en chunks y generamos sus embeddings.
- Creación de caché distribuida: Estos chunks y embeddings se guardan en una caché temporal (en nuestro caso, Redis), asociada a una sesión única.
- Recuperación desde la caché: Cuando el usuario hace preguntas, realizamos la búsqueda de similitud contra esta caché temporal.
- Generación aumentada: Los chunks recuperados se usan para aumentar el prompt del LLM.
Ventajas de CAG:
- Agilidad: Permite el análisis instantáneo de documentos.
- Aislamiento de contexto: El conocimiento del documento está aislado a la sesión actual.
- Eficiencia de costes: Evitamos costes de almacenamiento y cómputo para datos de un solo uso.
En esta sección, implementaremos un sistema CAG que permitirá a los usuarios subir un PDF y conversar sobre su contenido, utilizando una arquitectura robusta con LangChain.js y Upstash.
Ejercicio: Implementando un analizador de PDFs con arquitectura CAG distribuida
Paso 1: Configurar la infraestructura y dependencias
En este paso he elegido Upstash, tiene una capa gratuíta más que generosa y que se complementa perfectamente con el ecosistema de Vercel. Pero lo más importante es que no estaras ligado a un proveedor, podrás cambiar fácilmente el código para usar Redis como quieras.
- Crear una Base de Datos en Upstash:
- Ve a Upstash y crea una cuenta gratuita.
- Crea una nueva base de datos "Redis".
- Copia las URLs de conexión:
UPSTASHREDISRESTURLyUPSTASHREDISRESTTOKEN.
2. Añadir Credenciales a .env.local:
UPSTASH_REDIS_REST_URL="TU_URL_DE_UPSTASH_AQUI"
UPSTASH_REDIS_REST_TOKEN="TU_TOKEN_DE_UPSTASH_AQUI"3. Instalar Nuevas Dependencias:
pnpm install @upstash/redis langchain @langchain/community @langchain/google-genai pdf-parse uuid @types/uuidPaso 2: Crear el nuevo endpoint de API para CAG con LangChain
Crearemos src/app/api/pdf-chat/route.ts.
import { google } from '@ai-sdk/google';
import { streamText, convertToModelMessages, UIMessage, UIMessagePart, UIDataTypes, UITools, FileUIPart } from 'ai';
import { Redis } from '@upstash/redis';
import { z } from 'zod';
import { WebPDFLoader } from "@langchain/community/document_loaders/web/pdf";
import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
import { GoogleGenerativeAIEmbeddings } from "@langchain/google-genai";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { Document } from 'langchain/document';
export const maxDuration = 60;
const redis = new Redis({
url: process.env.UPSTASH_REDIS_REST_URL!,
token: process.env.UPSTASH_REDIS_REST_TOKEN!,
});
const extractPdfAsBlob = async (parts: UIMessagePart<UIDataTypes, UITools>[]): Promise<Blob | undefined> => {
const filePart = parts.find(part => part.type === 'file' && part.mediaType === 'application/pdf');
if (filePart) {
const x = await fetch((filePart as FileUIPart).url);
const y = new Blob([await x.blob()], { type: 'application/pdf' });
return y
}
return undefined;
};
const PostBodySchema = z.object({
messages: z.array(z.any()),
id: z.string(),
});
interface SerializedVectorStore {
docs: {
pageContent: string;
embedding: number[];
}[];
}
async function processAndCachePdf(pdfBlob: Blob, sessionId: string) {
console.log(`[CAG] Iniciando procesamiento de PDF para sessionId: ${sessionId}`);
const loader = new WebPDFLoader(pdfBlob);
const docs = await loader.load();
console.log(`[CAG] PDF cargado. Páginas: ${docs.length}`);
const splitter = new RecursiveCharacterTextSplitter({ chunkSize: 1024, chunkOverlap: 100 });
const chunks = await splitter.splitDocuments(docs);
console.log(`[CAG] Texto dividido en ${chunks.length} chunks.`);
if (chunks.length === 0) return;
const embeddings = new GoogleGenerativeAIEmbeddings({
apiKey: process.env.GOOGLE_GENERATIVE_AI_API_KEY,
modelName: "text-embedding-004"
});
const vectorStore = await MemoryVectorStore.fromDocuments(chunks, embeddings);
console.log('[CAG] VectorStore en memoria creado.');
const serializedVectorStore = JSON.stringify({
docs: vectorStore.memoryVectors.map((vector, i) => ({
pageContent: chunks[i].pageContent,
embedding: vector.embedding
})),
});
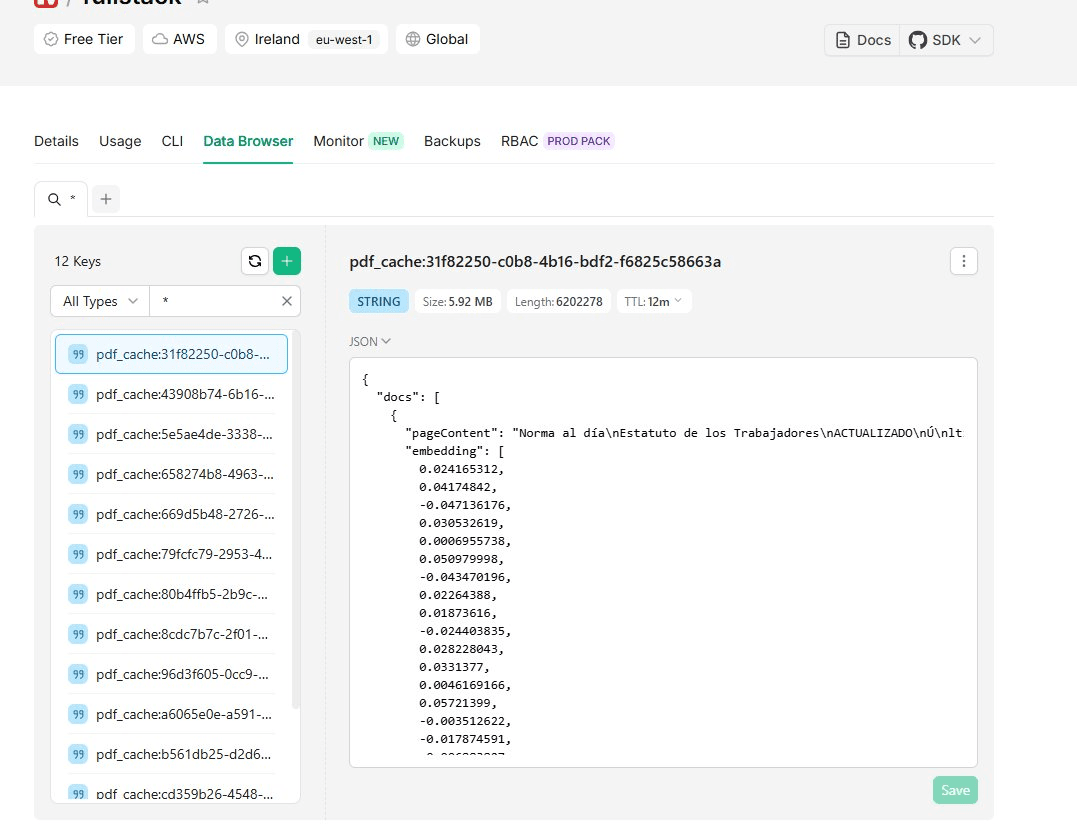
await redis.set(`pdf_cache:${sessionId}`, serializedVectorStore, { ex: 3600 });
console.log(`[CAG] VectorStore para sessionId ${sessionId} guardado en Redis.`);
}
async function findRelevantCachedChunks(query: string, sessionId: string): Promise<string[]> {
const serializedData = await redis.get<string>(`pdf_cache:${sessionId}`);
if (!serializedData) return [];
const serializedVectorStore: SerializedVectorStore = JSON.parse(serializedData as string);
const { docs } = serializedVectorStore;
const embeddings = new GoogleGenerativeAIEmbeddings({
apiKey: process.env.GOOGLE_GENERATIVE_AI_API_KEY,
modelName: "text-embedding-004"
});
const documents = docs.map(doc => new Document({ pageContent: doc.pageContent }));
const precomputedEmbeddings = docs.map(doc => doc.embedding);
const vectorStore = new MemoryVectorStore(embeddings);
await vectorStore.addVectors(precomputedEmbeddings, documents);
console.log(`[CAG] Buscando chunks relevantes para la query: "${query}"`);
const results = await vectorStore.similaritySearch(query, 4);
return results.map(result => result.pageContent);
}
export async function POST(req: Request) {
try {
const body = await req.json();
const validation = PostBodySchema.safeParse(body);
console.log('[CAG] Petición recibida:', validation);
if (!validation.success) {
return new Response(JSON.stringify(validation.error.flatten()), { status: 400 });
}
const { messages, id }: { messages: UIMessage[]; id: string } = validation.data;
const lastUserMessage = messages[messages.length - 1];
if (!lastUserMessage || !Array.isArray(lastUserMessage.parts)) {
return new Response("Mensaje de usuario inválido", { status: 400 });
}
const userText = lastUserMessage.parts.filter(part => part.type === 'text').map(part => part.text).join(' ');
const pdfBlob = await extractPdfAsBlob(lastUserMessage.parts);
console.log('[CAG] Texto del usuario:', userText);
console.log('[CAG] PDF adjunto:', pdfBlob ? 'Sí' : 'No');
if (pdfBlob) {
console.log(`[CAG] Procesando nuevo PDF para sessionId: ${id}`);
await processAndCachePdf(pdfBlob, id);
console.log(`[CAG] PDF procesado y cacheado para sessionId: ${id}`);
const result = streamText({
model: google('gemini-2.0-flash-001'),
prompt: "He procesado el documento PDF. ¿Qué te gustaría saber sobre él?"
});
console.log(`[CAG] Respuesta inicial enviada para sessionId: ${id}`);
return result.toUIMessageStreamResponse();
}
console.log(`[CAG] Buscando en caché para sessionId: ${id}`);
const relevantChunks = await findRelevantCachedChunks(userText, id);
console.log(`[CAG] Chunks relevantes encontrados: ${relevantChunks.length}`);
const context = relevantChunks.join('\n---\n');
const systemPrompt = `
Eres un asistente experto en analizar documentos. Responde a la pregunta del usuario basándote
únicamente en el siguiente contexto extraído del PDF que te ha proporcionado.
Si la respuesta no se encuentra en el contexto, indica amablemente que no puedes encontrar esa
información en el documento.
Contexto del Documento:
---
${context}
---
`;
console.log('[CAG] Llamando al modelo con el prompt y contexto.');
const result = await streamText({
model: google('gemini-2.0-flash-001'),
system: systemPrompt,
messages: convertToModelMessages(messages),
});
console.log(`[CAG] Respuesta generada para sessionId: ${id}`);
return result.toUIMessageStreamResponse();
} catch (error) {
console.error("Error en la API de PDF-Chat (CAG):", error);
return new Response("Error al procesar el PDF.", { status: 500 });
}
}Paso 3: Adaptar el frontend para manejar sesiones
Actualizamos src/hooks/useCustomChat.ts para que genere y envíe un sessionId con cada conversación.
import { useChat } from "@ai-sdk/react";
import { DefaultChatTransport, UIMessage, UIMessagePart, UIDataTypes, UITools } from "ai";
import {
useState,
ChangeEvent,
FormEvent,
useCallback,
useMemo,
} from "react";
import { v4 as uuidv4 } from 'uuid';
interface UseCustomChatProps {
api: string;
id?: string;
}
interface UseCustomChatResult {
input: string;
setInput: React.Dispatch<React.SetStateAction<string>>;
messages: UIMessage[];
sendMessage: (message: UIMessage) => void;
status: string;
handleInputChange: (e: ChangeEvent<HTMLTextAreaElement>) => void;
handleSubmit: (e: FormEvent<HTMLFormElement>, files?: File[]) => void;
}
const fileToDataURL = (file: File): Promise<string> => {
return new Promise((resolve, reject) => {
const reader = new FileReader();
reader.onload = () => resolve(reader.result as string);
reader.onerror = (error) => reject(error);
reader.readAsDataURL(file);
});
};
export const useCustomChat = ({ api, id }: UseCustomChatProps): UseCustomChatResult => {
const [input, setInput] = useState("");
const [sessionId] = useState(id || uuidv4());
const chat = useChat({
id: sessionId,
transport: useMemo(() => new DefaultChatTransport({ api }), [api]),
});
const handleInputChange = useCallback(
(e: ChangeEvent<HTMLTextAreaElement>) => setInput(e.target.value),
[setInput]
);
const handleSubmit = useCallback(
async (e: FormEvent<HTMLFormElement>, files: File[] = []) => {
e.preventDefault();
const trimmedInput = input.trim();
if (!trimmedInput && files.length === 0) return;
const messageParts: UIMessagePart<UIDataTypes, UITools>[] = [];
if (trimmedInput) {
messageParts.push({ type: 'text', text: trimmedInput });
}
// Procesar y añadir las imágenes
for (const file of files) {
const dataUrl = await fileToDataURL(file);
messageParts.push({
type: 'file',
mediaType: file.type,
filename: file.name,
url: dataUrl
});
}
if (messageParts.length > 0) {
chat.sendMessage({ role: 'user', parts: messageParts });
setInput("");
}
},
[chat, chat.sendMessage, input, setInput]
);
return {
input,
setInput,
messages: chat.messages,
sendMessage: chat.sendMessage,
status: chat.status,
handleInputChange,
handleSubmit,
};
};Análisis del hook actualizado:
- Se añade
uuidpara generar identificadores de sesión únicos por cada instancia del chat. - El
bodyde la petición deuseChatse modifica para incluir siempre elsessionId. -
handleSubmitahora convierte los PDFs aUint8Array, el formato que nuestro helperextractPdfBufferespera en el backend.
Paso 4: Crear la página del chat de PDFs
La página src/app/pdf-chat/page.tsx no cambia, ya que el componente Chatbot es genérico y el hook useCustomChat maneja la sesión de forma transparente. La dejamos tal y como la diseñamos en la respuesta anterior.
import { Chatbot } from "@/components/ui/Chatbot/Chatbot";
import { BotIcon, UserIcon } from 'lucide-react';
// Avatares (podrían estar en un archivo compartido)
const AssistantAvatar = () => (
<div className="w-8 h-8 bg-green-500 rounded-full flex items-center justify-center flex-shrink-0">
<BotIcon className="text-white w-5 h-5" />
</div>
);
const UserAvatar = () => (
<div className="w-8 h-8 bg-slate-500 rounded-full flex items-center justify-center flex-shrink-0">
<UserIcon className="text-white w-5 h-5" />
</div>
);
export default function PdfChatPage() {
return (
<Chatbot
apiEndpoint="/api/pdf-chat"
assistantName="Analizador de Documentos"
assistantDescription="Sube un PDF y hazme preguntas sobre él."
assistantAvatar={<AssistantAvatar />}
userAvatar={<UserAvatar />}
initialMessageTitle="Listo para analizar tu PDF"
initialMessageDescription="Sube un documento para empezar nuestra conversación."
inputPlaceholder="Adjunta un PDF o haz una pregunta sobre el documento actual..."
fileSupport={true}
accept='application/pdf'
/>
);
}Prueba del caso de uso: Conversando con un documento
- Ejecuta la aplicación:
pnpm devy navega ahttp://localhost:3000/pdf-chat. - Sube un PDF: Usa el botón del clip para subir un archivo PDF.
- Observa la consola del servidor: Verás los logs de
[CAG], mostrando el procesamiento del PDF y su almacenamiento en Redis.
4. Recibe la respuesta inicial: El asistente confirmará que ha procesado el documento.
5. Haz Preguntas: Formula preguntas sobre el contenido del PDF. Cada pregunta desencadenará una búsqueda en la caché de Redis y una respuesta contextualizada.
6. Prueba la persistencia de sesión: Copia la URL de tu navegador (que no contendrá un ID de sesión). Refresca la página. La conversación se reiniciará. Esto es correcto, porque el sessionId se genera en el cliente. Ahora, abre la misma URL en una nueva pestaña. Será una sesión completamente diferente con su propia caché. Si subes un PDF en la primera pestaña y haces preguntas, la segunda pestaña no sabrá nada de ese documento, demostrando el aislamiento de sesiones.
Conclusión del capítulo
Hemos alcanzado un hito en la madurez de nuestra arquitectura. Al pasar de una caché en memoria a una solución distribuida con Redis y LangChain.js, hemos construido un sistema CAG que no solo es potente, sino también escalable y robusto, listo para un entorno de producción.
Logros Clave de esta Parte:
- Integración de LangChain.js: Has aprendido a integrar una librería de alto nivel en una aplicación de AI SDK.
- Implementación de una caché distribuida: Has configurado y utilizado Upstash Redis, resolviendo los problemas de estado en arquitecturas serverless.
- Gestión de sesiones: Has implementado un sistema de sesiones, un requisito no negociable para aplicaciones multiusuario.
Con un agente que puede ver, leer y analizar documentos sobre la marcha de forma escalable, estamos preparados para el capítulo final de sus capacidades: las Function Calling y Herramientas.
Podrás encontrar el código de este artículo en: https://github.com/aperezl/ai-fullstack-serie/tree/rag-pdf