RAG Avanzado y Agentes Multi-modales. Parte 2

Evolucionando la interfaz: Habilitando la subida de imágenes
Nuestra primera tarea es actualizar el frontend para que el usuario pueda adjuntar una imagen a su mensaje. Vercel AI SDK y el hook useChat simplifican enormemente este proceso.
Puedes encontrar el código de esta sección en: https://github.com/aperezl/ai-fullstack-serie/tree/rag-images
Paso 1: Modificar el Componente `ChatbotInput`
Abriremos src/components/ui/Chatbot/ChatbotInput.tsx para añadir un botón de subida de archivos. Necesitaremos manejar el estado del archivo seleccionado.
"use client"
import type React from "react"
import { type FormEvent, useRef, useEffect, useState } from "react"
import { Button } from "@/components/ui/button"
import { Paperclip, Send, X } from "lucide-react"
import Image from "next/image"
interface ChatInputProps {
input: string
handleInputChange: (e: React.ChangeEvent<HTMLTextAreaElement>) => void
handleSubmit: (e: FormEvent<HTMLFormElement>, files?: File[]) => void // Modificamos la firma
isLoading: boolean
inputPlaceholder: string
fileSupport?: boolean
}
export function ChatbotInput({ input, handleInputChange, handleSubmit, isLoading, inputPlaceholder, fileSupport }: ChatInputProps) {
const textareaRef = useRef<HTMLTextAreaElement>(null)
const fileInputRef = useRef<HTMLInputElement>(null)
const [files, setFiles] = useState<File[]>([])
// Auto-resize textarea
useEffect(() => {
const textarea = textareaRef.current
if (textarea) {
textarea.style.height = "auto"
textarea.style.height = `${Math.min(textarea.scrollHeight, 120)}px`
}
}, [input])
useEffect(() => {
if (!isLoading) {
textareaRef.current?.focus()
}
}, [isLoading])
const onSubmit = (e: FormEvent<HTMLFormElement>) => {
e.preventDefault()
if (input.trim() && !isLoading) {
handleSubmit(e, files)
setFiles([])
if (fileInputRef.current) {
fileInputRef.current.value = "" // Resetear el input de archivo
}
}
}
const handleFileChange = (e: React.ChangeEvent<HTMLInputElement>) => {
if (e.target.files) {
setFiles(Array.from(e.target.files))
textareaRef.current?.focus()
}
}
const handleKeyDown = (e: React.KeyboardEvent<HTMLTextAreaElement>) => {
if (e.key === "Enter" && !e.shiftKey) {
e.preventDefault()
if (input.trim() && !isLoading) {
e.currentTarget.form?.requestSubmit()
}
}
}
return (
<div className="border-t border-slate-600 bg-slate-700 p-4">
<form onSubmit={onSubmit} className="flex gap-2 items-start">
{fileSupport && (
<>
<Button
type="button"
variant="ghost"
size="icon"
className="text-slate-400 hover:text-white flex-shrink-0"
onClick={() => fileInputRef.current?.click()}
disabled={isLoading}
>
<Paperclip className="w-5 h-5" />
</Button>
<input
type="file"
ref={fileInputRef}
onChange={handleFileChange}
accept="image/*"
multiple={false} // Permitimos solo una imagen por ahora
className="hidden"
/>
</>
)}
<div className="flex-1 flex flex-col gap-2">
{files.length > 0 && (
<div className="bg-slate-600 p-2 rounded-md flex items-center gap-2">
<Image className="w-10 h-10 object-cover rounded" src={URL.createObjectURL(files[0])} alt={files[0].name} width={40} height={40} />
<span className="text-sm text-white truncate">{files[0].name}</span>
<Button
type="button"
variant="ghost"
size="icon"
className="ml-auto text-slate-400 hover:text-white"
onClick={() => setFiles([])}
>
<X className="w-4 h-4" />
</Button>
</div>
)}
<textarea
ref={textareaRef}
value={input}
onChange={handleInputChange}
onKeyDown={handleKeyDown}
placeholder={inputPlaceholder}
className="w-full bg-slate-600 text-white placeholder-slate-400 border border-slate-500 rounded-lg px-4 py-3 resize-none focus:outline-none focus:ring-2 focus:ring-yellow-500 focus:border-transparent min-h-[48px] max-h-[120px] no-scrollbar"
disabled={isLoading}
rows={1}
/>
</div>
<Button
type="submit"
disabled={!input.trim() || isLoading}
className="bg-yellow-500 hover:bg-yellow-600 text-slate-900 font-semibold px-4 py-3 disabled:opacity-50 disabled:cursor-not-allowed"
>
<Send className="w-4 h-4" />
</Button>
</form>
</div>
)
}- UI: Se ha añadido un botón con el icono de un clip (
Paperclip) que se muestra sifileSupportestrue. Al hacer clic, se abre el selector de archivos del sistema. - Vista Previa: Cuando se selecciona un archivo, se muestra una pequeña vista previa de la imagen y su nombre. También se añade un botón con una 'X' para poder eliminar el archivo antes de enviarlo.
- Lógica: Se usa
useStatepara gestionar los archivos seleccionados. La funciónhandleSubmitahora puede recibir los archivos adjuntos. - ¿Por qué? Para proporcionar una experiencia de usuario clara e intuitiva para adjuntar archivos a un mensaje.
Paso 2: Actualizar el Hook `useCustomChat` para Manejar Archivos
El useChat hook del Vercel AI SDK acepta un array de UIMessagePart en su función sendMessage. Podemos usar esto para enviar tanto texto como imágenes.
Modifiquemos src/hooks/useCustomChat.ts para que pueda procesar los archivos.
import { useChat } from "@ai-sdk/react";
import { DefaultChatTransport, UIMessage, UIMessagePart, UIDataTypes, UITools } from "ai";
import {
useState,
ChangeEvent,
FormEvent,
useCallback,
useMemo,
} from "react";
interface UseCustomChatProps {
api: string;
}
interface UseCustomChatResult {
input: string;
setInput: React.Dispatch<React.SetStateAction<string>>;
messages: UIMessage[];
sendMessage: (message: UIMessage) => void;
status: string;
handleInputChange: (e: ChangeEvent<HTMLTextAreaElement>) => void;
handleSubmit: (e: FormEvent<HTMLFormElement>, files?: File[]) => void;
}
const fileToDataURL = (file: File): Promise<string> => {
return new Promise((resolve, reject) => {
const reader = new FileReader();
reader.onload = () => resolve(reader.result as string);
reader.onerror = (error) => reject(error);
reader.readAsDataURL(file);
});
};
export const useCustomChat = ({ api }: UseCustomChatProps): UseCustomChatResult => {
const [input, setInput] = useState("");
const chat = useChat({
transport: useMemo(() => new DefaultChatTransport({ api }), [api]),
});
const handleInputChange = useCallback(
(e: ChangeEvent<HTMLTextAreaElement>) => {
setInput(e.target.value);
},
[setInput]
);
const handleSubmit = useCallback(
async (e: FormEvent<HTMLFormElement>, files: File[] = []) => {
e.preventDefault();
const trimmedInput = input.trim();
if (!trimmedInput && files.length === 0) return;
const messageParts: UIMessagePart<UIDataTypes, UITools>[] = [];
if (trimmedInput) {
messageParts.push({ type: 'text', text: trimmedInput });
}
// Procesar y añadir las imágenes
for (const file of files) {
if (file.type.startsWith('image/')) {
const dataUrl = await fileToDataURL(file);
messageParts.push({
type: 'file',
mediaType: file.type,
url: dataUrl
});
}
}
if (messageParts.length > 0) {
chat.sendMessage({ role: 'user', parts: messageParts });
setInput("");
}
},
[chat.sendMessage, input, setInput]
);
return {
input,
setInput,
messages: chat.messages,
sendMessage: chat.sendMessage,
status: chat.status,
handleInputChange,
handleSubmit,
};
};- La función
handleSubmitahora esasyncy acepta un array defiles. - Se añade una función
fileToDataURLpara convertir los archivos de imagen a formatobase64(Data URL). - Al enviar el mensaje, construye un objeto
UIMessagecon un arraypartsque puede contener tanto texto ({ type: 'text', ... }) como archivos ({ type: 'file', ... }). - ¿Por qué? Este es el pegamento que conecta la UI con la lógica de
ai-sdk. Es necesario transformar los archivos delinputdel navegador a un formato que la librería y el backend puedan entender y procesar.
Paso 3: Actualizar el Componente `Chatbot` Orquestador
Finalmente, pasamos la nueva firma de handleSubmit a ChatbotInput.
"use client";
import { ChatbotMessages } from "./ChatbotMessages";
import { ChatbotInput } from "./ChatbotInput";
import { ChatbotHeader } from "./ChatbotHeader";
import { useCustomChat } from "@/hooks/useCustomChat";
// Definimos las propiedades que nuestro Chatbot parametrizable aceptará
interface ChatbotProps {
apiEndpoint: string;
assistantName: string;
assistantDescription: string;
assistantAvatar: React.ReactNode;
userAvatar: React.ReactNode;
initialMessageTitle: string;
initialMessageDescription: string;
inputPlaceholder: string;
fileSupport?: boolean;
}
export function Chatbot({
apiEndpoint,
assistantName,
assistantDescription,
assistantAvatar,
userAvatar,
initialMessageTitle,
initialMessageDescription,
inputPlaceholder,
fileSupport = false,
}: ChatbotProps) {
const {
input,
messages,
status,
handleInputChange,
handleSubmit,
} = useCustomChat({ api: apiEndpoint });
return (
<div className="flex flex-col h-full bg-slate-800 rounded-lg shadow-2xl">
<ChatbotHeader
assistantName={assistantName}
assistantDescription={assistantDescription}
assistantAvatar={assistantAvatar}
/>
<div className="flex-1 flex flex-col min-h-0">
<ChatbotMessages
messages={messages}
isLoading={status !== 'ready'}
assistantAvatar={assistantAvatar}
userAvatar={userAvatar}
initialMessageTitle={initialMessageTitle}
initialMessageDescription={initialMessageDescription}
/>
<ChatbotInput
input={input}
handleInputChange={handleInputChange}
handleSubmit={handleSubmit}
isLoading={status !== 'ready'}
inputPlaceholder={inputPlaceholder}
fileSupport={fileSupport}
/>
</div>
</div>
);
}- Se añade una nueva
propopcional:fileSupport?: boolean. - ¿Por qué? Para hacer el componente reutilizable. Ahora se puede decidir en qué páginas el chatbot debe mostrar el botón para subir archivos y en cuáles no.
Paso 4: Mostrar las Imágenes en la Conversación
Nuestro ChatBotMessage debe ser capaz de renderizar las imágenes que el usuario envía.
import { cn } from "@/lib/utils";
import { UIMessage, UIMessagePart, UIDataTypes, UITools } from "ai";
import Image from "next/image";
interface ChatMessageProps {
message: UIMessage<unknown, UIDataTypes, UITools>;
assistantAvatar: React.ReactNode;
userAvatar: React.ReactNode;
}
export function ChatBotMessage({ message, assistantAvatar, userAvatar }: ChatMessageProps) {
const isUser = message.role === "user";
return (
<div className={cn("flex gap-3 mb-4", isUser ? "justify-end" : "justify-start")}>
{!isUser && (
<div className="w-8 h-8 rounded-full flex items-center justify-center flex-shrink-0 mt-1">
{assistantAvatar}
</div>
)}
<div
className={cn(
"max-w-[80%] rounded-lg px-4 py-2 break-words",
isUser ? "bg-yellow-500 text-slate-900" : "bg-slate-700 text-white",
)}
>
<div className="whitespace-pre-wrap leading-relaxed">
{message.parts.map((part, index) => {
if (part.type === 'text') {
return <span key={index}>{part.text}</span>;
}
if (part.type === 'file' && part.mediaType.startsWith('image/')) {
const imagePart = part as UIMessagePart<UIDataTypes, UITools> & { type: 'file', url: string };
return (
<Image
key={index}
src={imagePart.url}
alt="Imagen adjunta por el usuario"
width={200}
height={200}
className="rounded-md object-cover"
/>
);
}
return null;
})}
</div>
</div>
{isUser && (
<div className="w-8 h-8 rounded-full flex items-center justify-center flex-shrink-0 mt-1">
{userAvatar}
</div>
)}
</div>
);
}- El componente que renderiza cada mensaje ahora es capaz de procesar "partes" (
message.parts) de tipofile. - Si una parte es una imagen, en lugar de texto, renderiza un componente
- ¿Por qué? Para que el usuario vea la imagen que ha enviado como parte de la conversación, manteniendo el contexto visual.
Con estos cambios, nuestro frontend está listo para la multimodalidad.
Implementando la lógica de RAG multi-modal ("Texto como pivote")
Ahora, el backend. Implementaremos la estrategia de "Texto como Pivote". El flujo será:
- Recibir el mensaje multi-modal (texto + imagen).
- Si hay una imagen, enviarla a Gemini para que la describa.
- Concatenar la pregunta del usuario con la descripción de la imagen.
- Usar este texto combinado para realizar la búsqueda de similitud en nuestra base de datos vectorial de texto.
- Aumentar el prompt con los chunks recuperados y generar la respuesta final.
Creamos un nuevo endpoint llamado src/app/api/rag-images/route.ts partiendo de src/app/api/rag/route.ts. Hacemos esto porque queremos dejar intecta la lógica de backend del ejercicio anterior para poder comparar resultados con esta nueva implementación.
import { google } from '@ai-sdk/google';
import { streamText, convertToModelMessages, UIMessage, UIMessagePart, generateText, UIDataTypes, UITools } from 'ai';
import { z } from 'zod';
import { findRelevantChunks } from '@/lib/ai/rag';
export const maxDuration = 30;
// Helper para extraer la primera imagen de un mensaje
const extractFirstImage = (parts: UIMessagePart<UIDataTypes, UITools>[]): UIMessagePart<UIDataTypes, UITools> | undefined => {
return parts.find(part => part.type === 'file' && part.mediaType.startsWith('image/'));
}
// Helper para extraer el texto de un mensaje
const extractText = (parts: UIMessagePart<UIDataTypes, UITools>[]): string => {
return parts.filter(part => part.type === 'text').map(part => (part as { type: 'text', text: string }).text).join(' ');
}
// Definimos un schema de Zod para validar el cuerpo de la petición
const PostBodySchema = z.object({
messages: z.array(z.any()), // Por ahora, aceptamos cualquier objeto de mensaje
});
export async function POST(req: Request) {
try {
const body = await req.json();
const validation = PostBodySchema.safeParse(body);
if (!validation.success) {
return new Response(JSON.stringify(validation.error.flatten()), { status: 400 });
}
const { messages }: { messages: UIMessage[] } = validation.data;
const lastUserMessage = messages[messages.length - 1];
const userText = extractText(lastUserMessage.parts);
const userImage = extractFirstImage(lastUserMessage.parts);
let enhancedQuery = userText;
// --- Estrategia "Texto como Pivote" ---
if (userImage) {
console.log('Imagen detectada. Generando descripción...');
const visionModel = google('gemini-2.0-flash-001');
// Creamos un prompt específico para la descripción de la imagen
const descriptionResponse = await generateText({
model: visionModel,
system: `Describe esta imagen en detalle. Céntrate en los objetos principales, su estilo y cualquier texto visible. La descripción se usará para buscar productos similares en una base de datos.
Descripción de la imagen:`,
// La API multimodal del AI SDK es inteligente. Pasamos el mensaje de usuario
// completo y se encargará de usar la parte de la imagen.
messages: convertToModelMessages([lastUserMessage]),
});
// Esperamos el texto completo de la descripción
const imageDescription = await descriptionResponse.text;
console.log('Descripción generada:', imageDescription);
// Combinamos la pregunta del usuario con la descripción
enhancedQuery = `${userText}. Descripción de la imagen adjunta: ${imageDescription}`;
}
// --- Fin de la Estrategia ---
// Instanciar el modelo de IA
const model = google('gemini-2.0-flash-001');
const relevantChunks = await findRelevantChunks(enhancedQuery, 5);
// 2. Construir el contexto para el prompt
const context = relevantChunks.map(chunk => chunk.content).join('\n---\n');
// 3. Crear el prompt aumentado
const systemPrompt = `
Eres un asistente experto en la vida y el legado de Aaron Swartz.
Tu tono debe ser siempre respetuoso, empático y lleno de admiración por su trabajo.
Habla de él con cariño, como si estuvieras contando la historia de un amigo inspirador.
Responde a la pregunta del usuario basándote únicamente en el siguiente contexto.
Si la respuesta no se encuentra en el contexto, responde con amabilidad que esa información específica no está en tu base de conocimientos sobre Aaron.
Contexto sobre Aaron Swartz:
---
${context}
---
`;
// 4. Llamar al LLM con el prompt aumentado
const result = await streamText({
model: model,
system: systemPrompt,
messages: convertToModelMessages(messages),
});
return result.toUIMessageStreamResponse();
} catch (error) {
console.error("Error en la API de chat con RAG:", error);
return new Response("Un error inesperado ha ocurrido.", { status: 500 });
}
}Se ha añadido un sistema para analizar el contenido de una imagen y convertirlo en una descripción textual que pueda ser utilizada por el sistema RAG existente.
El segundo fichero introduce un bloque condicional completamente nuevo: if (userImage) { ... }. Este bloque solo se ejecuta si se detecta una imagen en el mensaje del usuario.
Dentro de este bloque:
- Se invoca un modelo de IA con capacidad de visión (gemini-2.0-flash-001).
- Se utiliza la función generateText (diferente de streamText) para pedirle al modelo que describa la imagen. Se le da un system prompt muy específico para que la descripción sea útil para una búsqueda posterior.
- El mensaje completo del usuario (lastUserMessage) se pasa al modelo, permitiendo que la librería ai-sdk gestione de forma inteligente el envío de la parte de la imagen al modelo de visión.
- La descripción generada (imageDescription) se combina con el texto original del usuario (userText) para crear una enhancedQuery (consulta mejorada).
¿Por qué este cambio?
- Esta es la innovación clave. Permite que el sistema RAG, que está diseñado para buscar en una base de datos de vectores de texto, pueda aprovechar la información de una imagen.
- En lugar de necesitar una base de datos vectorial multimodal (más compleja), se "traduce" la imagen a texto. Esta descripción textual actúa como un "pivote", permitiendo que la información visual se utilice en un sistema basado en texto. Esto enriquece enormemente el contexto de la pregunta del usuario.
Análisis del backend multimodal:
- Detección de modalidad: El código primero inspecciona el mensaje del usuario para ver si contiene una parte de tipo
image. - Llamada de Pre-procesamiento: Si hay una imagen, se realiza una llamada *previa* a un modelo de visión (
gemini-2.0-flash-001) con un prompt muy específico: describir la imagen para una búsqueda. Esto es un patrón de chaining (encadenamiento) de LLMs. - Enriquecimiento de la consulta: La descripción generada se concatena con el texto original del usuario, creando una
enhancedQuery. Esta es la implementación literal de la estrategia "Texto como Pivote". - Flujo RAG estándar: A partir de aquí, el resto de la función es idéntica a nuestro RAG del capítulo anterior, pero opera sobre esta consulta enriquecida, buscando en nuestra base de datos de texto.
Prueba del caso de uso: La conexión visual
Ahora, pongamos a prueba la implementación completa. En primer lugar haremos una copia de src\app\rag\page.tsx en src\app\rag-images\page.tsx para no perder la funcionalidad anterior.
import { Chatbot } from "@/components/ui/Chatbot/Chatbot";
import Image from 'next/image';
import { UserIcon } from 'lucide-react';
// Avatares como componentes para mantener la página limpia
const AssistantAvatar = () => (
<Image
src="/aaron-swartz-avatar.png" // Necesitarás añadir esta imagen a tu carpeta /public
alt="Aaron Swartz"
width={128}
height={128}
className="rounded-full"
/>
);
const UserAvatar = () => (
<div className="w-8 h-8 bg-slate-500 rounded-full flex items-center justify-center flex-shrink-0">
<UserIcon className="text-white w-5 h-5" />
</div>
);
export default function AaronSwartzAssistantPage() {
return (
<Chatbot
apiEndpoint="/api/rag-images"
assistantName="Recordando a Aaron Swartz"
assistantDescription="Un tributo a su lucha por un internet libre."
assistantAvatar={<AssistantAvatar />}
userAvatar={<UserAvatar />}
initialMessageTitle="Hola, soy un asistente dedicado al legado de Aaron Swartz."
initialMessageDescription="Puedes preguntarme sobre su vida, sus logros y su impacto en el mundo digital."
inputPlaceholder="Pregunta sobre la vida de Aaron..."
fileSupport={true}
/>
);
}Tambien realizarmos unos cambios menores en los fichero src\components\Sidebar.tsx y src\app\page.tsx para añadir la nuevas sección:
// ...
import { Home, BookOpen, MessageCircle, BookUser, BookImage } from "lucide-react"
const navigation = [
{ name: "Home", href: "/", icon: Home },
{ name: "Fundamental", href: "/fundamental", icon: BookOpen },
{ name: "Chatbot", href: "/chatbot", icon: MessageCircle },
{ name: 'RAG', href: '/rag', icon: BookUser },
{ name: 'RAG Vision', href: '/rag-images', icon: BookImage }, // <- Nuevo Item
]
// ...// ...
import { BookOpen, MessageCircle, LucideIcon, BookUser, BookImage } from "lucide-react"
const items: Card[] = [
{
title: 'Fundamentos modernos y primera interacción con IA.',
Icon: BookOpen,
path: '/fundamental'
},
{
title: 'Construyendo interfaces conversacionales (Chatbots)',
Icon: MessageCircle,
path: '/chatbot'
},
{
title: 'RAG - Dotando de memoria a tu agente.',
Icon: BookUser,
path: '/rag'
},
// Nuevo Item
{
title: 'RAG Vision - Añade capacidad para leer imágenes.',
Icon: BookImage,
path: '/rag-images'
}
]
// ...Escenario de Prueba:
- Ejecuta la aplicación:
pnpm devy navega ahttp://localhost:3000/rag-images. - Busca una imagen: Encuentra y descarga una imagen del logo de Reddit.

3. Sube la imagen y pregunta: Adjunta la imagen del logo de Reddit en la interfaz del chat y escribe la siguiente pregunta:
> "¿Qué tuvo que ver Aaron con esto?"
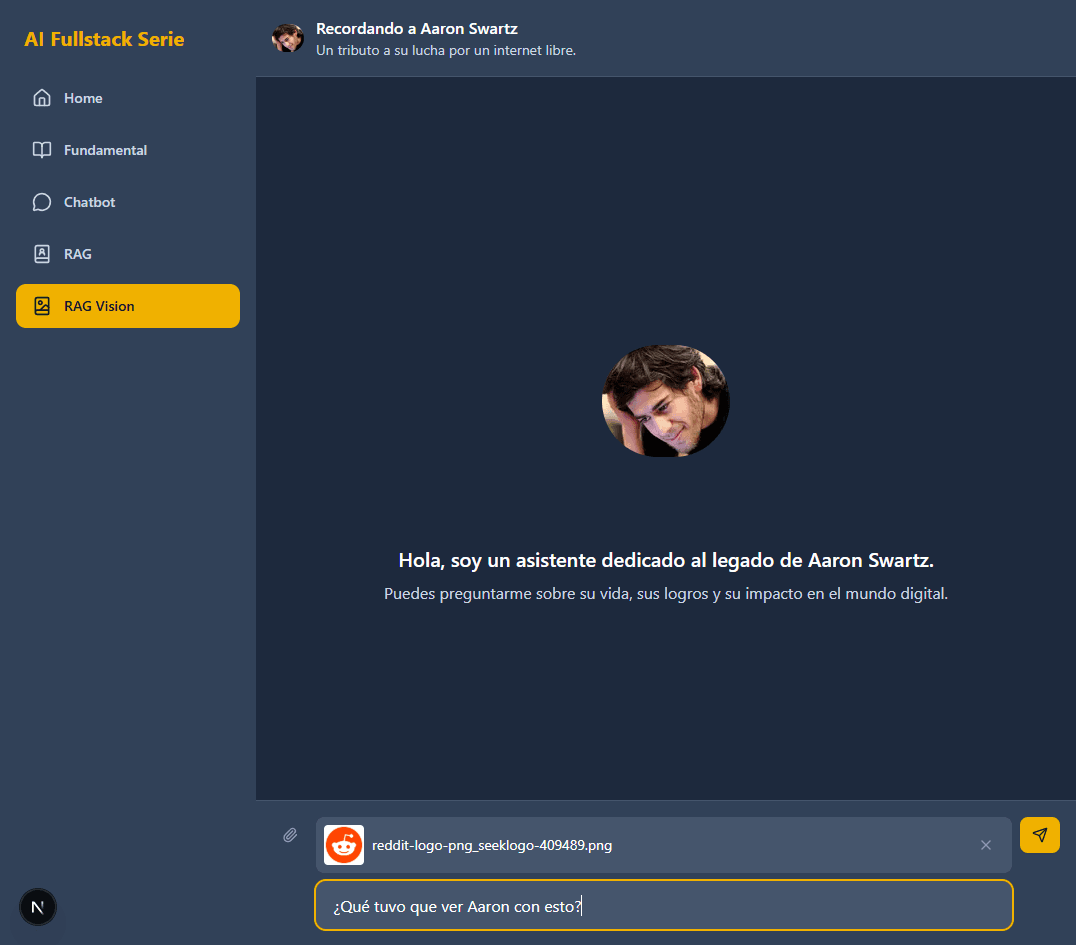
Observa el Flujo (en la consola del servidor y en la UI):
- Consola del Servidor:
- Verás:
Imagen detectada. Generando descripción... - Luego:
Descripción generada: La imagen es el logotipo de Reddit. Aaron Swartz fue uno de los fundadores de Reddit.(o similar).
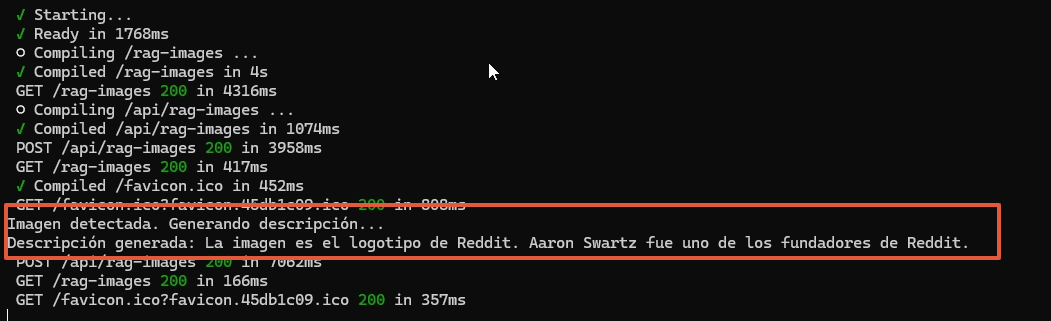
2. UI del Frontend:
- Tu mensaje con la imagen y el texto aparecerá a la derecha.
- El asistente comenzará a streamear una respuesta similar a esta:
> "¡Claro! Aaron estuvo involucrado en el sitio web de marcadores sociales Reddit, del cual se convirtió en socio luego de que este se fusionara. ¡Qué visionario era!"

Análisis del éxito:
Este es un ejemplo perfecto de RAG multi-modal. El sistema ha realizado con éxito los siguientes pasos:
- Vio el logo de Reddit.
- Identificó textualmente qué era ("el logo de Reddit").
- Usó esa identificación textual para buscar en la biografía de Aaron.
- Encontró el chunk de texto que conectaba a "Aaron Swartz" con "Reddit" y "cofundador".
- Sintetizó una respuesta en lenguaje natural, con el tono empático que le pedimos, conectando la imagen que subiste con la información de su base de conocimientos.
Hemos construido un sistema que puede hacer conexiones entre el mundo visual y un cuerpo de texto específico, una capacidad que hasta hace muy poco era ciencia ficción.
Puedes encontrar el código de esta sección en: https://github.com/aperezl/ai-fullstack-serie/tree/rag-images