RAG Avanzado y Agentes Multi-modales. Parte 1

Introducción: De un agente bibliotecario a un detective
En el capítulo anterior, transformamos nuestro agente de un simple conversador a un investigador de textos, un "bibliotecario" capaz de consultar una base de conocimientos para formular respuestas. Sin embargo, el mundo real —y los datos que lo describen— rara vez se componen únicamente de texto. Vivimos en un universo de imágenes, diagramas, vídeos y sonidos. Una aplicación verdaderamente inteligente debe ser capaz de percibir y razonar sobre esta rica variedad de información.
Este capítulo marca una evolución fundamental en la capacidad de nuestro agente. Pasaremos de un modelo que solo "lee" a uno que también "ve". Abordaremos el concepto de multimodalidad: la capacidad de un sistema de IA para procesar y relacionar información de diferentes tipos de datos (o modalidades), principalmente texto e imágenes.
Desde una perspectiva de arquitectura de software, esto introduce un nuevo nivel de complejidad. Ya no se trata solo de procesar strings, sino de manejar datos binarios, entender la semántica visual y fusionar insights de diferentes fuentes en un único contexto coherente. Exploraremos:
- La mecánica interna de los modelos multimodales: ¿Cómo un modelo como Gemini 2.5 Pro logra "entender" una imagen en conjunción con un prompt de texto?
- Arquitecturas para RAG multi-modal: ¿Cómo extendemos nuestro sistema RAG existente para incorporar conocimiento visual? Analizaremos dos estrategias fundamentales con sus respectivos tradeoffs.
- El desafío de los documentos complejos: El mundo real no son solo archivos
.md. ¿Cómo extraemos de manera fiable texto, tablas e imágenes de formatos complejos como el PDF para alimentar nuestro sistema RAG?
Al final de este capítulo, nuestro agente habrá dado un paso de gigante: de ser un bibliotecario que busca en fichas, se convertirá en un detective que puede analizar la "escena del crimen" visual y textual para llegar a conclusiones más profundas.
La fusión de píxeles y proposiciones: Entendiendo los modelos multi-modales
Un modelo de lenguaje tradicional opera en un espacio de "proposiciones": secuencias de tokens que representan conceptos lingüísticos. Un modelo multi-modal, como la familia Gemini, opera en un espacio latente unificado, donde tanto las proposiciones textuales como los patrones visuales de los píxeles pueden ser representados y comparados.
¿Cómo "ve" un LLM?
El proceso, aunque conceptualmente complejo, puede simplificarse en varios pasos:
- Codificación visual (Vision Encoding): La imagen de entrada no se procesa como un todo. Primero, se descompone en una cuadrícula de fragmentos más pequeños o "patches".
- Embedding de patches: Cada patch se pasa a través de una red neuronal (un codificador de visión, a menudo basado en la arquitectura Vision Transformer o ViT) que lo convierte en un vector, un embedding, de manera similar a como se hace con los tokens de texto. Este vector captura las características visuales del patch (colores, texturas, formas).
- Proyección al espacio común: Estos embeddings visuales se proyectan en el mismo espacio vectorial de alta dimensionalidad que los embeddings de los tokens de texto. Ahora, el vector para el patch de una imagen que muestra un "cielo azul" está conceptualmente "cerca" del vector para los tokens de texto "cielo" y "azul".
- Atención cruzada (Cross-Attention): Aquí reside la magia. La arquitectura Transformer del modelo utiliza mecanismos de "atención" no solo para relacionar palabras entre sí (atención de texto) o patches de imagen entre sí (atención de visión), sino también para relacionar palabras con patches de imagen (atención cruzada). Cuando el modelo procesa el token "gato" en el prompt, el mecanismo de atención "presta más atención" a los patches de la imagen que el codificador visual ha identificado como semánticamente relacionados con un gato.
El Contrato de la API Multi-modal
Para nosotros, como ingenieros, esta complejidad se abstrae en una simple modificación del contrato de la API. El Vercel AI SDK lo maneja elegantemente. Mientras que un mensaje de usuario textual es un simple string, un mensaje multi-modal se representa como un array de "partes" dentro del content.
// Mensaje de usuario en el hook useChat
const userMessage: UIMessage = {
id: '...',
role: 'user',
parts: [
{ type: 'text', text: '¿Tenéis productos similares a este pero en azul?' },
{ type: 'image', image: 'data:image/jpeg;base64,...' } // Imagen como data URL
]
};El AI SDK se encarga de serializar este objeto en el formato que la API del proveedor (en este caso, Google Gemini) espera, permitiendo que nuestra lógica de aplicación maneje la multimodalidad de forma limpia y estructurada.
Arquitecturas para RAG multi-modal: Dos estrategias fundamentales
Extender nuestro sistema RAG para que maneje imágenes no es trivial. Requiere una decisión de diseño arquitectónico. Existen dos enfoques principales:
Estrategia 1: "Texto como pivote" (Text as a Pivot)
Esta es la estrategia más directa y, a menudo, la más práctica de implementar. En lugar de realizar una búsqueda vectorial visual, utilizamos un VLM (Vision-Language Model) como un pre-procesador para convertir la información visual en texto, que luego se integra en nuestra pipeline de RAG textual existente.
Diagrama de flujo:
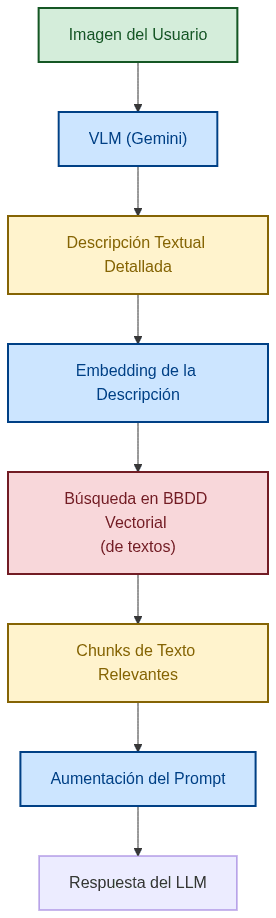
Ventajas:
- Reutilización de infraestructura: Nos permite seguir usando nuestra base de datos vectorial de
pgvectorexistente, que solo almacena embeddings de texto. - Simplicidad: La lógica de búsqueda no cambia. Simplemente enriquecemos la consulta del usuario con una descripción generada por la IA.
Desventajas:
- Pérdida de información (Information Loss): La calidad del RAG depende totalmente de la calidad de la descripción textual. Matices visuales sutiles (un estilo artístico particular, una textura específica) pueden perderse en la traducción de imagen a texto.
- Latencia y coste adicional: Introduce una llamada extra a un LLM al principio de la pipeline de recuperación, lo que incrementa el coste y el tiempo de respuesta.
Estrategia 2: "Búsqueda vectorial nativa" (Native Vector Search)
Este es el enfoque "verdaderamente" multi-modal. En lugar de convertir imágenes a texto, convertimos tanto las imágenes como los textos a embeddings en un espacio vectorial compartido y realizamos la búsqueda directamente en ese espacio.
Diagrama de Flujo:
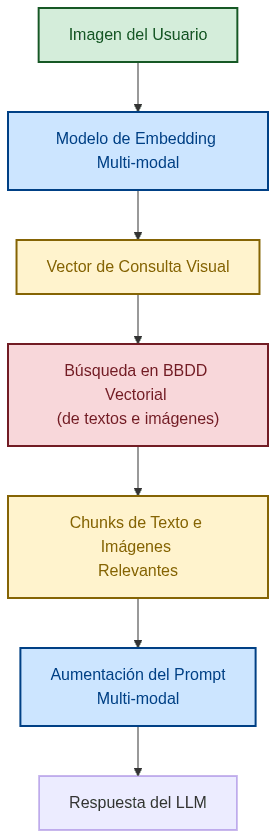
Ventajas:
- Riqueza semántica: La búsqueda es mucho más potente. Puede encontrar relaciones conceptuales entre una imagen y un texto que una simple descripción textual omitiría. Por ejemplo, una foto de una playa caribeña podría coincidir con un chunk de texto que describe "vacaciones tropicales relajantes" sin mencionar explícitamente una playa.
Desventajas:
- Infraestructura compleja: Requiere un modelo de embedding capaz de procesar tanto texto como imágenes (como
gemini-embedding-001). Además, nuestra base de datospgvectornecesitaría almacenar embeddings de ambos tipos y potencialmente metadatos que indiquen la fuente (texto o imagen). - Ecosistema menos maduro: Las herramientas y las mejores prácticas para la búsqueda vectorial nativamente multi-modal están todavía en desarrollo activo.
Nuestra decisión arquitectónica: Para esta serie, nos centraremos en la Estrategia 1 ("Texto como pivote"). Representa el equilibrio perfecto entre la potencia de la multimodalidad y la pragmática de la ingeniería, permitiéndonos obtener resultados impresionantes con una complejidad de infraestructura manejable.
Más allá del markdown: El desafío de los documentos complejos (PDFs)
Nuestra pipeline de ingesta actual asume documentos de texto limpios como Markdown. Sin embargo, el conocimiento empresarial a menudo reside en formatos de presentación como el PDF. Extraer texto de un PDF no es tan simple como leer un archivo.
El problema del PDF: Un PDF es un formato de "presentación", no de "contenido". Su propósito es describir con precisión dónde colocar caracteres y gráficos en una página. No contiene inherentemente información sobre la estructura semántica (qué es un párrafo, qué es un encabezado, el orden de lectura de las columnas, etc.). Una extracción de texto ingenua a menudo produce un galimatías de texto desordenado.
Técnicas de procesamiento avanzado:
- Análisis de layout (Layout Analysis): Las herramientas modernas de extracción de PDFs no solo leen el texto, sino que analizan la disposición (layout) de la página para inferir el orden de lectura correcto, identificar encabezados, pies de página (y descartarlos), y reconstruir párrafos que se extienden por varias columnas o páginas.
- Extracción de tablas: Las tablas son un desafío particular. Las herramientas avanzadas pueden identificar las estructuras de filas y columnas y extraer los datos en un formato estructurado (como JSON o CSV), que puede ser procesado de forma diferente al texto narrativo.
- OCR (Reconocimiento óptico de caracteres): Para PDFs que son imágenes escaneadas de documentos, se necesita una capa de OCR para convertir los píxeles de los caracteres en texto digital.
- Modelos de inteligencia de documentos: La solución más avanzada es usar modelos de IA especializados (a menudo VLMs) que pueden "mirar" la página del PDF y no solo extraer el texto, sino también entender su estructura. Estos modelos pueden devolver una representación estructurada (ej. JSON) del documento, separando párrafos, tablas, títulos y listas.
Para un sistema RAG robusto, una pipeline de ingesta profesional debe incorporar estas técnicas avanzadas para asegurar que el contenido que se divide en chunks y se vectoriza sea semánticamente coherente y limpio.
Conclusión de la parte teórica
Hemos expandido nuestro universo de datos más allá del texto. Hemos comprendido que la multimodalidad no es una característica añadida, sino un cambio fundamental en cómo un agente puede percibir y procesar la información.
Hemos establecido una estrategia arquitectónica clara (RAG con "Texto como Pivote") que nos permitirá implementar estas capacidades de forma práctica. También hemos reconocido que la calidad de un sistema RAG es directamente proporcional a la calidad de su pipeline de ingesta, y que manejar documentos del mundo real requiere herramientas más sofisticadas que un simple lector de archivos.
Con esta base teórica, estamos listos para llevar nuestro chatbot al siguiente nivel práctico: construir una interfaz que acepte imágenes y un backend que pueda razonar sobre ellas.