Function Calling y Herramientas (Tools). Parte 1

Introducción: De la sabiduría a la acción
Hasta ahora, nuestro agente ha sido un experto pasivo. Puede entender texto, analizar imágenes, consultar su memoria (RAG) y discutir documentos (CAG). Puede, en esencia, saber cosas. Pero saber no es lo mismo que *hacer*. La verdadera utilidad de un agente avanzado no reside solo en su capacidad para responder preguntas, sino en su habilidad para realizar tareas, interactuar con otros sistemas y efectuar cambios en el mundo digital.
Este capítulo marca el paso de un agente de conocimiento a un agente de acción. Introduciremos el concepto de Herramientas (Tools), también conocido como Function Calling. Este es el mecanismo que permite a un LLM ir más allá de la generación de texto para invocar funciones de código predefinidas y actuar basándose en sus resultados.
Desde una perspectiva de ingeniería de software, esto es un cambio monumental. Estamos delegando una parte del flujo de control de nuestra aplicación al razonamiento del LLM. El modelo ya no solo genera contenido, sino que emite directivas estructuradas que desencadenan lógica de negocio en nuestro backend. Los desafíos que abordaremos son:
- El contrato de la herramienta (Tool Contract): ¿Cómo describimos una función de nuestro código (ej.
getUserFromDatabase(id: string)) de una manera que un LLM pueda entender, invocar de forma fiable y con los argumentos correctos? - El ciclo de razonamiento-acción (Reason-Act Loop): ¿Cuál es el patrón arquitectónico para manejar la decisión del LLM de usar una herramienta, ejecutarla de forma segura y devolverle el resultado para que pueda continuar su razonamiento?
- La seguridad como prioridad: Al permitir que un LLM invoque nuestro código, abrimos una nueva superficie de ataque potencial. ¿Cómo diseñamos un sistema que sea a la vez potente y seguro?
El Vercel AI SDK, junto con la biblioteca zod, nos proporciona un framework elegante y seguro para implementar este patrón. Al final de este capítulo, nuestro agente podrá conectarse a APIs externas, consultar bases de datos en tiempo real y, en definitiva, actuar como un verdadero asistente digital.
El mecanismo de Function Calling: Cómo un LLM aprende a usar nuestro código
El Function Calling es una capacidad afinada en los LLMs modernos. No es que el modelo ejecute nuestro código. Más bien, ha sido entrenado para reconocer cuándo una pregunta o instrucción del usuario puede ser resuelta por una de las *herramientas* que le hemos proporcionado, y para generar una estructura de datos (generalmente JSON) que representa una llamada a esa función con los argumentos adecuados.
El flujo de decisión del LLM:
- Disponibilidad de herramientas: En nuestra llamada a la API del LLM, junto con el prompt y el historial de mensajes, incluimos una descripción de las herramientas disponibles. Esta descripción es un esquema formal (similar a una especificación OpenAPI o un JSON Schema) que detalla el nombre de cada herramienta, su propósito y los parámetros que acepta, incluyendo sus tipos y si son obligatorios.
2. Intención del usuario: El LLM analiza el prompt del usuario. Por ejemplo: "Busca el correo electrónico de Jane Doe y envíale una invitación para la reunión de mañana a las 10 AM".
3. Proceso de razonamiento interno (Chain of Thought): El modelo razona internamente (esto no lo vemos directamente). Piensa algo como:
- "La tarea tiene dos partes: buscar un email y enviar una invitación."
- "Para buscar el email, necesito el nombre 'Jane Doe'. ¿Tengo una herramienta para buscar usuarios? Sí, la herramienta
getUserByFullName." - "Para enviar la invitación, necesito el email, la fecha y la hora. ¿Tengo una herramienta para enviar emails? Sí, la herramienta
sendEmail." - "Primero debo usar
getUserByFullNamepara obtener el email. Luego, con ese email, podré usarsendEmail."
4. Generación de la llamada a la herramienta: En lugar de generar una respuesta de texto, el LLM detiene su generación de texto y devuelve un objeto especial en la respuesta de la API. Este objeto indica qué herramienta quiere usar y con qué argumentos.
Ejemplo de respuesta de la API del LLM (simplificado):
{
"finish_reason": "tool_calls",
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "getUserByFullName",
"arguments": "{\"fullName\":\"Jane Doe\"}"
}
}
]
}Es crucial entender que el LLM solo ha generado este JSON de intención. No ha ejecutado nada. Nuestra aplicación es la que recibe esta respuesta.
El ciclo de orquestación: El patrón `tool` de Vercel AI SDK
Nuestra responsabilidad como ingenieros es implementar el ciclo que maneja esta "intención" del LLM. El Vercel AI SDK nos proporciona una abstracción de alto nivel, la función tool, que simplifica enormemente esta orquestación.
Definiendo una herramienta con `tool` y `zod`
La función tool nos permite definir una herramienta completa —su esquema, su descripción y su lógica de ejecución— en un único objeto autocontenido.
import { tool } from 'ai';
import { z } from 'zod';
const myDatabaseTool = tool({
// 1. El esquema de entrada (Input Schema)
inputSchema: z.object({
userId: z.string().describe("El ID del usuario a buscar."),
}),
// 2. La descripción
description: 'Busca un usuario en la base de datos por su ID.',
// 3. La lógica de ejecución
execute: async ({ userId }) => {
// Aquí va nuestro código de backend real
const user = await db.users.find({ where: { id: userId } });
if (!user) {
return { success: false, message: 'Usuario no encontrado.' };
}
return { success: true, user: { name: user.name, email: user.email } };
},
});Análisis de la definición:
-
inputSchemaconzod: Este es el contrato. Define la "firma" de nuestra función. El AI SDK lo convertirá internamente al formato JSON Schema que el LLM necesita. El uso de.describe()es vital; esta descripción es la que el LLM leerá para entender qué significa cada parámetro. -
description: Esta es la descripción de alto nivel de la herramienta. El LLM la usa para decidir cuándo es apropiado usar esta herramienta. Una buena descripción es la clave para unfunction callingpreciso. -
execute: Esta es la función de JavaScript/TypeScript real que se ejecutará en nuestro servidor cuando el LLM decida llamar a la herramienta. Recibe un objeto con los argumentos ya validados contra elinputSchema.
El ciclo completo (Reason-Act Loop)
Cuando pasamos un objeto de herramientas a streamText o generateText, el AI SDK automatiza el siguiente ciclo:
Diagrama de Flujo del Ciclo de Herramientas:
[Pregunta del Usuario] -> [1. Llamada al LLM con Herramientas] -> [2. LLM decide usar Herramienta A] -> [AI SDK recibe la intención] -> [3. AI SDK valida los argumentos vs. Schema] -> [4. AI SDK invoca la función 'execute' de la Herramienta A] -> [5. 'execute' devuelve un resultado] -> [6. AI SDK formula un nuevo mensaje (rol 'tool')] -> [7. AI SDK vuelve a llamar al LLM con el resultado] -> [8. LLM genera la respuesta final en texto]
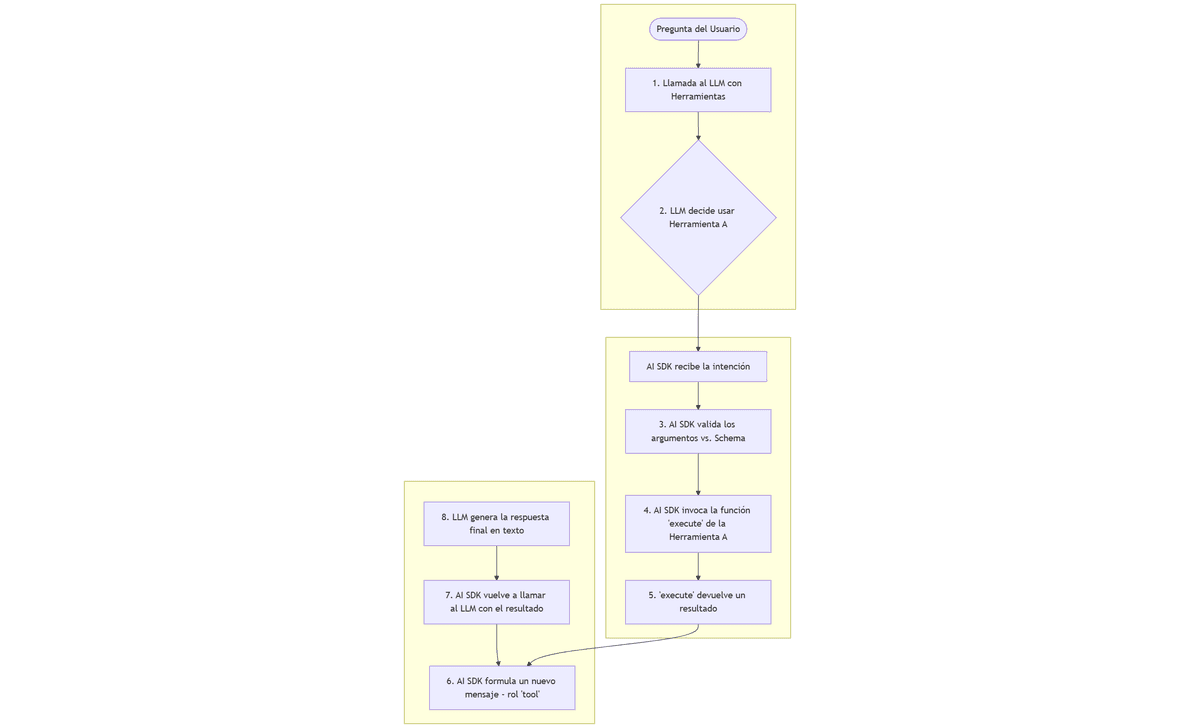
- Paso 6: El mensaje de rol
tool: Este paso es crucial. Después de ejecutar la herramienta, el SDK no termina el proceso. Construye un nuevo mensaje especial en el historial de la conversación, conrole: 'tool', que contiene el resultado de la ejecución. - Paso 7: La segunda llamada al LLM: El SDK vuelve a llamar al LLM, pero esta vez el historial de mensajes contiene la pregunta original del usuario, la decisión de la IA de usar la herramienta, y el resultado de esa herramienta.
- Paso 8: La síntesis final: Con toda esta información, el LLM ahora tiene el contexto completo para formular una respuesta final en lenguaje natural para el usuario. Por ejemplo: "He encontrado a la usuaria. Su correo es jane.doe@example.com. Procederé a enviarle la invitación."
Este ciclo puede repetirse. Un LLM avanzado puede decidir, tras ver el resultado de la primera herramienta, que necesita llamar a una segunda herramienta antes de poder dar la respuesta final. El AI SDK gestiona estos bucles multi-paso de forma automática.
Diseño y seguridad de herramientas: Una perspectiva senior
Permitir que un modelo de lenguaje invoque nuestro código es una capacidad inmensa, y con un gran poder viene una gran responsabilidad.
- Principio de mínimo privilegio: Cada herramienta debe tener el acceso más restringido posible. Una herramienta para leer datos de usuarios no debería tener permisos de escritura.
- Idempotencia: Siempre que sea posible, las herramientas deben ser idempotentes. Si el LLM, por alguna razón, llama a
cancelarSuscripcion(userId: '123')dos veces, el resultado debería ser el mismo que si la llamara una vez. - Validación rigurosa: Aunque el LLM genera los argumentos, nunca debemos confiar ciegamente en ellos. Nuestro
inputSchemade Zod es nuestra primera línea de defensa. La lógica dentro deexecutedebe realizar comprobaciones adicionales (ej. ¿eluserIdproporcionado pertenece al usuario autenticado actual?). - Herramientas de solo lectura vs. herramientas de escritura: Es una buena práctica separar claramente las herramientas que leen datos de las que modifican el estado. Para las herramientas de escritura, se pueden implementar patrones más seguros, como requerir un paso de confirmación humana (que veremos en capítulos posteriores sobre LangGraph).
- Evitar efectos secundarios peligrosos: Nunca se debe dar a un LLM acceso directo y sin restricciones a herramientas como
exec(ejecutar un comando de shell) oeval(evaluar un string de código). Cualquier ejecución de código debe estar fuertemente "sandboxeada" y limitada.
Conclusión teórica
Hemos añadido la pieza que faltaba para que nuestro agente sea verdaderamente útil: la capacidad de actuar. Hemos entendido que el "Function Calling" no es ejecución de código por parte de la IA, sino una generación de intención estructurada que nuestra aplicación debe orquestar.
Hemos aprendido que el patrón tool del Vercel AI SDK encapsula esta orquestación de forma elegante y segura, manejando el ciclo completo de razonamiento, validación, ejecución y síntesis. Lo más importante es que hemos establecido los principios de seguridad y diseño robusto que son indispensables al construir el puente entre el razonamiento no determinista de un LLM y la lógica determinista de nuestro backend.
Con esta comprensión, estamos listos para pasar a la práctica y construir un agente que pueda interactuar con una API externa para realizar tareas útiles en nombre del usuario.